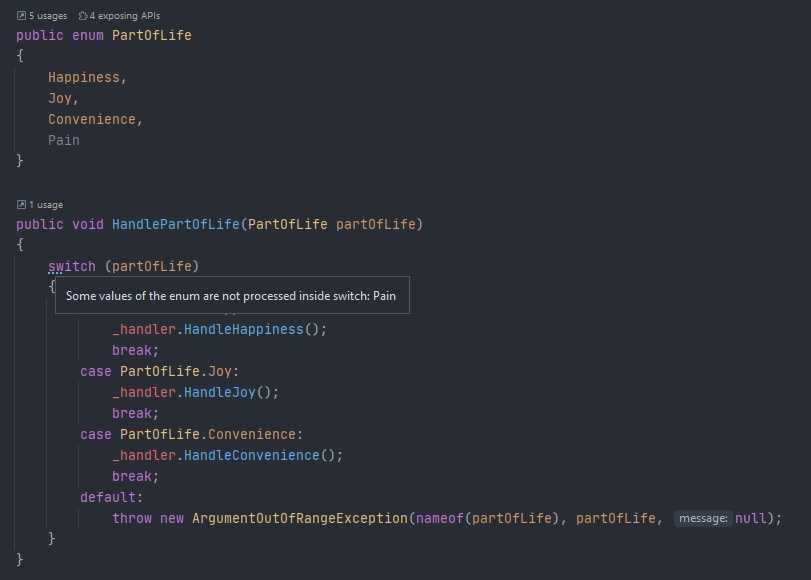
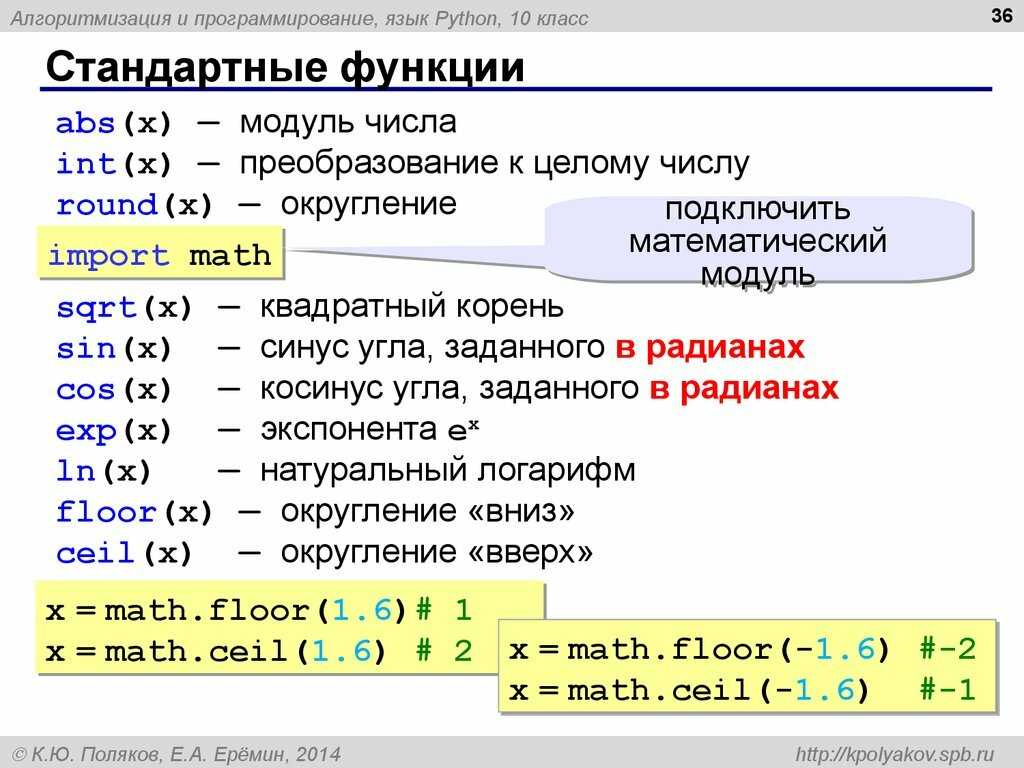
В чем отличия и связь «Искусственного интеллекта» и «Машинного обучения»?[править]
Машинное обучение – одно из направлений Искусственного Интеллекта. Данное направление состоит из методов, которые позволяют делать выводы на основе данных.
Искусственный интеллект – одно из направлений Машинного Обучения. Данное направление занимается имитированием поведения человека.
Искусственный Интеллект и Машинное Обучение – это направления Глубокого обучения нейронных сетей.
Искусственный Интеллект – это алгоритмы, связанные с обучением цифровых нейронных сетей. Машинное обучение — это алгоритмы работы с табличными данными.
Искусственный Интеллект занимается задачами имитации деятельности мозга человека. Машинное обучение – это процесс, в ходе которого обучается Искусственный Интеллект. +
Что такое цифровая экономика?[править]
Хозяйственная деятельность, в которой ключевым фактором являются данные в цифровом виде +
Стадия развития технологий интернет, концепция вычислительной сети физических предметов («вещей»), оснащенных встроенными технологиями для взаимодействия друг с другом или с внешней средой и объединяющая целый стек технологий
Общий подход к цифровой трансформации и внедрению управления на основе данных на промышленном предприятии
Подход к цифровой трансформации компании, основанный на решении использовать современные технологии и практики проектной работы
Направление, в котором стартапы, инновационные компании и само государство оцифровывают государственные продукты и услуги, используя новые технологии
Техники скоринга
ICE Scoring
- Impact — влияние на продукт либо с точки зрения бизнеса, либо сколько денег принесет, либо что эта фича даст, насколько она крутая. Параметр задается в диапазоне от 1 до 10.
- Confidence — уверенность в оценке сложности или в оценке влияния фичи. Например, вы придумали какую-то функцию и думаете, что она хорошо повлияет на проект. Аналитики не было, данные неточные и пока приоритет основывается только на вашем личном мнении. Чем ниже уверенность в вашем личном мнении, тем ниже показатель. Задается также в диапазоне от 1 до 10.
- Ease — трудозатраты или простота реализации. Также задается от 1 до 10. Чем проще функция, тем у нее выше балл.
Влияние
- она улучшает конверсии,
- она привлекает новых пользователей,
- она удерживает существующих пользователей,
- она добавляет ценности продукту.
Уверенность
- личном мнении, мнении команды, мнении сторонних экспертов;
- UX-исследованиях;
- опросах;
- интервью;
- наблюдениях, в том числе — за конкурентами;
MVP; - A/B-тестах;
- сторонних исследованиях;
- аналитике;
- топовых обращениях в техподдержку;
- топовых запросах от сейлз-менеджеров;
- топовых запросах клиентов.
ПлюсыМинусы
RICE Scoring
- Reach — охват: сколько пользователей у нас от этой фичи получат хоть какое-то удовлетворение, либо заметят эту фичу, либо будут ей пользоваться. Можно измерять количественно: например, 500 миллионов пользователей ощутят на себе эту функцию. Можно измерять в процентном отношении — например, 30% пользователей будет использовать эту фичу.
- Impact — влияние: насколько эта функция на самом деле нам нужна, насколько она нам поможет, насколько функция крутая.
- Confidence — уверенность: аналогично с ICE Scoring, уверенность в наших оценках и прогнозе влияния.
- Effort — трудоемкость.
Оценка задач
-
Игра престолов
Приходит какой-то «верховный босс» и говорит, что из бэклога должно быть сделано прямо сейчас, и спускает вам оценки сверху. Это может быть технический директор, который расставляет оценки всех задач и говорит, что какая-то задача делается за столько-то, такая-то за столько-то. Или это можете быть вы сами
Такое часто встречается (хотя сами мы так стараемся не делать). Обычно по ходу декомпозиции какие-то вещи уточняются, появляются какие-то детали и нюансы. Часто с этими оценками могут быть не согласны разработчики или реальность может быть немножко сложнее, чем вы себе запланировали. Плюс у бизнеса всегда есть подсознательное понимание, за какое количество часов он готов купить эту фичу, а за какое уже не готов (и это всегда где-то на грани). -
Оценка из теории вероятности
Берутся три оценки по времени: оптимистичная, пессимистичная и реалистичная, и строится график, называемый Гауссианой.Для расчета наиболее вероятной оценки применяют формулу: (Оптимистичная + (Реалистичная * 3) + Пессимистичная) / 6.
В идеале наиболее вероятная оценка будет чуть дальше, чем реалистичная.
Нюанс в том, что не доказано, что в результате у нас получится нормальное распределение. Например, если взять группу людей и измерить их рост, то получится кривая, как на графике ниже: очень маленьких людей мало, очень высоких людей — тоже мало. И они не входят в норму. Остальные в выделенном диапазоне — и есть нормальное распределение.
Гауссиана подразумевает, что варианты, когда задача выйдет за отметку пессимистичной оценки или вообще никогда не будет сделана, стремительно уменьшаются. Но в ИТ-среде часто бывают задачи, которые, на первый взгляд, сделать «невозможно» — программисты для них требуют поменять постановку либо продолжают доказывать эту невозможность. Другая ситуация — человек оценил задачу в 1 час, потратил всё мыслимое и немыслимое время и пришёл к выводу, что не может сделать эту задачу.
Поэтому опираться на этот метод можно, но по факту это та же «игра престолов», да и сложновато по каждой задаче давать три оценки плюс считать по формуле. И нет никакой гарантии, что в итоге всё не выйдет за рамки этих оценок и расчётов. -
Planning Poker
Это наиболее простой и «чистенький» способ получить нормальные оценки, обсудить какие-то фичи, нюансы, детали. Даже на верхнем уровне по бэклогу можно такое проделать.Минус Planning Poker — это довольно ресурсоемкая операция, поскольку нужно собирать всю команду вместе и читать бэклог. Но если вы применяете методы вроде Story Mapping, вам всё равно нужно собираться командой и делать предварительные оценки (хотя бы в днях, неделях — крупных величинах).Плюсы Planning Poker- оценки распределяются в зависимости от опыта сотрудника, и здесь можно договориться;
- оценки даются сначала закрыто, и только потом открываются — нет давления авторитета (как в случае с оценками, спущенными «сверху»).

Практическое применение
Давайте рассмотрим пример сервиса с целевой надежностью в 99,99% и проработаем требования как к его компонентам, так и к работе с его сбоями.
Цифры
Предположим, что ваш 99,99-процентно доступный сервис имеет следующие характеристики:
Одно крупное отключение и три незначительных отключения в год
Это звучит пугающе, но обратите внимание, что целевой уровень надежности в 99,99% подразумевает один 20-30-минутный масштабный простой и несколько коротких частичных отключений в год. (Математика указывает, что: а) отказ одного сегмента не считается отказом всей системы с точки зрения SLO и б) общая надежность вычисляется суммой надежности сегментов.)
Пять критических компонентов в виде других независимых сервисов с надежностью 99,999%.
Пять независимых сегментов, которые не могут отказать друг за другом.
Все изменения проводятся постепенно, по одному сегменту за раз.
Математический расчет надежности будет выглядеть следующим образом:
Требования к компонентам
- Суммарный лимит ошибок за год составляет 0,01 процента от 525 600 минут в год, или 53 минуты (на основе 365-дневного года, при наихудшем сценарии).
- Лимит, выделяемый на отключения критических компонентов, составляет пять независимых критических компонентов с лимитом 0,001% каждый = 0,005%; 0,005% от 525 600 минут в год, или 26 минут.
- Оставшийся лимит ошибок вашего сервиса составляет 53-26=27 минут.
Требования к реагированию на отключения
- Ожидаемое количество простоев: 4 (1 полное отключение и 3 отключения, затрагивающие только один сегмент)
- Совокупное воздействие ожидаемых отключений: (1×100%) + (3×20%) = 1.6
- Время обнаружения сбоя и восстановления после него: 27/1.6 = 17 минут
- Время, выделенное мониторингу на обнаружение сбоя и оповещение о нем: 2 минуты
- Время, данное дежурному специалисту чтобы начать анализировать оповещение: 5 минут. (Система мониторинга должна отслеживать нарушения SLO и посылать сигнал на пейджер дежурному каждый раз, когда в системе происходит сбой. Многие сервисы Google находятся на поддержке посменных дежурных SR-инженеров, которые реагируют на срочные вопросы.)
- Оставшееся время для эффективной минимизации отрицательных последствий: 10 минут
Уточнение «Правила дополнительных девяток» для вложенных компонентов
Случайный читатель может сделать вывод, что каждое дополнительное звено в цепочке зависимостей требует дополнительных девяток, так что для зависимостей второго порядка требуется две дополнительные девятки, для зависимостей третьего порядка — три дополнительные девятки и т. д.










Это неверный вывод. Он основан на наивной модели иерархии компонентов в виде дерева с постоянным разветвлением на каждом уровне. В такой модели, как показано на рис. 1, имеется 10 уникальных компонентов первого порядка, 100 уникальных компонентов второго порядка, 1 000 уникальных компонентов третьего порядка и т. д., что приводит к созданию в общей сложности 1 111 уникальных сервисов, даже если архитектура ограничена четырьмя слоями. Экосистема высоконадежных сервисов с таким количеством независимых критических компонентов явно нереалистична.
Рис. 1 — Иерархия компонентов: Неверная модель
Критический компонент сам по себе может вызвать сбой всего сервиса (или сегмента сервиса) независимо от того, где он находится в дереве зависимостей. Поэтому, если данный компонент X отображается как зависимость нескольких компонентов первого порядка, X следует считать только один раз, так как его сбой в конечном итоге приведет к сбою службы независимо от того, сколько промежуточных сервисов будут также затронуты.
Корректное прочтение правила выглядит следующим образом:
- Если сервис имеет N уникальных критических компонентов, то каждый из них вносит 1/N в ненадежность всего сервиса, вызванную этим компонентом, невзирая на то, как низко он расположен в иерархии компонентов.
- Каждый компонент должен учитываться только один раз, даже если он несколько раз появляется в иерархии компонентов (другими словами, учитываются только уникальные компоненты). Например, при подсчете компонентов Сервиса А на рис. 2, Сервис Б следует учитывать только раз.
Рис. 2 — Компоненты в иерархии
Например, рассмотрим гипотетический сервис A с лимитом ошибок 0,01 процента. Владельцы сервиса готовы потратить половину этого лимита на собственные ошибки и потери, а половину — на критические компоненты. Если сервис имеет N таких компонентов, то каждый из них получает 1/N оставшегося лимита ошибок. Типичные сервисы часто имеют от 5 до 10 критических компонентов, и поэтому каждый из них может отказать только в одной десятой или одной двадцатой степени от лимита ошибок Сервиса A. Следовательно, как правило, критические части сервиса должны иметь одну дополнительную девятку надежности.
Лимиты ошибок
Концепция лимитов ошибок довольно подробно освещена в книге SRE, но и здесь следует ее упомянуть. SR-инженеры Google используют лимиты ошибок, чтобы сбалансировать надежность и темпы внедрения обновлений. Этот лимит определяет допустимый уровень отказа для сервиса в течение некоторого периода времени (обычно — месяц). Лимит ошибок — это просто 1 минус SLO сервиса, поэтому ранее обсуждавшаяся 99,99-процентно доступная служба имеет 0,01% «лимита» на ненадежность. До тех пор, пока сервис не израсходовал свой лимит ошибок в течение месяца, команда разработчиков свободна (в пределах разумного) запускать новые функции, обновления и т. д.
Если лимит ошибок израсходован, внесение изменений в сервис приостанавливается (за исключением срочных исправлений безопасности и изменений, направленных на то, что вызвало нарушение в первую очередь), пока служба не восполнит запас в лимите ошибок или пока не сменится месяц. Многие сервисы в Google используют метод скользящего окна для SLO, чтобы лимит ошибок восстанавливался постепенно. Для серьёзных сервисов с SLO более 99,99%, целесообразно применять ежеквартальное, а не ежемесячное обнуление лимита, поскольку количество допустимых простоев у них невелико.
Лимиты ошибок устраняют напряженность в отношениях между отделами, которая в противном случае могла бы возникнуть между SR-инженерами и разработчиками продукта, предоставляя им общий, основанный на данных механизм оценки риска запуска продукта. Они также дают и SR-инженерам, и командам разработки общую цель развития методов и технологий, которые позволят внедрять нововведения быстрее и запускать продукты без «раздувания бюджета».
Глобальный приоритет (Global Severity)
Глобальный приоритет (Global Severity) бага определяется 3-мя составляющими:
— Серьезность (Severity) — свойство тестового артефакта, характеризующее влияние артефакта на работоспособность приложения. Является характеристикой, определяемой с точки функциональности.
— Приоритет (Priority)- свойство тестового артефакта, влияющее на очередность выполнения задачи или устранения дефекта. Является характеристикой, определяемой с точки зрения бизнеса.
— Частота (Frequency) — свойство тестового артефакта, характеризующее частоту (%) возникновения при использовании приложения конечными пользователями. Является характеристикой, определяемой с точки зрения пользовательских сценариев использования продукта.
Таким образом, глобальный приоритет определяется на основании значений трёх свойств:
Далее рассмотрим более подробно данную зависимость и уточним ее.
Что такое «тест Тьюринга»?[править]
Тест, в ходе которого, через анонимную коммуникацию, человек или группа должны определить, обладает ли компьютер сознанием человека.
Тест, в ходе которого, через анонимную коммуникацию, человек или группа должны определить, может ли компьютер вести диалог с человеком.
Тест, в ходе которого, через анонимную коммуникацию, компьютер должен определить, общается ли с ним человек или другая программа.
Тест, в ходе которого, через анонимную коммуникацию, человек или группа должны определить, с кем общаются – с компьютером или человеком. +
Тест, в ходе которого, через анонимную коммуникацию, компьютер должен определить, каким уровнем интеллекта обладает человек.
Назовите три шага по созданию концепции цифровой трансформации?[править]
Анализ инфраструктуры – Создание технологического видения – Временная оценка преобразований, исходя из динамики изменения внешней среды
Диагностика текущего состояния – Формирование целевого состояние – Разработка дорожной карты преобразования +
Определение состояния продуктов и процессов – Создание стратегического видения – Временная оценка преобразований, исходя из текущего состояния организации
Изучение кадрового потенциала и культуры – Создание бизнес-архитектуры – Определение вех цифровой трансформации
Извлечение данных – Трансформация данных – Загрузка данных
Законы
Закон Голла
Работающая сложная система обязательно произошла от работавшей простой системы. Сложная система, разработанная с нуля, никогда не работает, и её невозможно исправить так, чтобы она заработала. Нужно начать заново, с простой работающей системы.







Закон Гудхарта
Любая наблюдаемая статистическая закономерность склонна разрушаться, как только на неё оказывается давление с целью управления ею.
Когда мерило становится целью, оно перестаёт быть хорошим мерилом.
Мэрилин Стратерн
- Тесты без утверждений удовлетворяют ожиданиям по покрытию кода, несмотря на то, что такая метрика создавалась для того, чтобы программа была хорошо проверена.
- Оценка эффективности разработчика на основе количества строк, внесённых в проект, приводит к неоправданному раздуванию кода.
Цикл шумихи и закон Амара
Мы склонны переоценивать влияние технологии в краткосрочной перспективе и недооценивать его в долгосрочной.
После появления технологии её популярность доходит до пика раздутых ожиданий, затем ныряет во впадину разочарования, поднимается по склону просветления и выходит на плато продуктивности
Закон Хирама
При достижении достаточного количества пользователей API уже неважно, какие его особенности вы обещали всем: для любой из возможных особенностей поведения вашей системы найдётся зависящий от неё пользователь.
Закон Кернигана
Отладка кода в два раза тяжелее, чем его написание. Поэтому, если вы пишете код на пределе умственных возможностей, вам, по определению, не хватит ума, чтобы его отлаживать.
Закон Мёрфи
Всё, что может пойти не так, пойдёт не так.
Если что-то может пойти не так, это случится, причём в наихудший из возможных моментов.
Закон Патта
В технологическом секторе доминируют два типа людей: те, кто разбирается в том, что они не контролируют, и те, кто контролирует то, в чём они не разбираются.
В любой технической иерархии со временем вырабатывается инверсия компетентности.
Открытые вопросы Рефлексии[править]
-
- Обоснуйте свою позицию, расскажите, что именно из услышанного вы считаете значимым. Социально-значимый эффект, практическая польза, масштабность решения, новизна и т.п. Выделите критерий, на основе которого вы выделяете какой-то контент.
Как вы планируете применять полученные в ходе интенсива знания в вашей дальнейшей работе?
-
- Опишите, как и в каких процессах, для каких целей и/или задач вы можете использовать тот или иной пример, материал или решение, с которыми вы познакомились в рамках интенсива.
Какие вопросы, рассмотренные в рамках интенсива, вы бы хотели более детально изучить в ближайшее время и почему?
Методы приоритизации задач
Story Mapping
Где и как применятьПлюсы Story Mapping
Метод позволяет построить связи в системе, на основе которых потом проще формировать спринты.
Когда много стейкхолдеров и много людей, у которых есть интересы в проекте, метод позволяет договориться о реальных приоритетах — что более важно, а что менее.
Value & Effort (или Lean Prioritization) для идей
-
Значимость фичи
Значимость каждой фичи с точки зрения бизнеса — это примерно то же, что и «ценность для бизнеса» в обычном бэклоге. Величина оценивается в условных единицах, лучше всего — в деньгах. В целом, любой параметр, который вы оптимизируете, можно брать за Value. Это может быть количество пользователей, которых вы привлечете в проект, или уменьшение оттока пользователей в проекте. -
Количество усилий, которое необходимо затратить на каждую из фич
Тоже можно считать, что это оценка в часах (estimate), как в бэкглоге. Но можно измерять и в Story Point-ах (сравнительная оценка требований относительно друг друга) или в человеко-часах.
Где и как применять
- он сам запутался,
- он генерирует странные идеи и требования,
- у него есть определенное ограничение по бюджету, и он не понимает, как лучше его распределить.
MoSCoW
M — Must HaveS — Should HaveC — Could HaveW — Would Have
Пример
Допустим, вы разрабатываете автомобиль. Must Have будут колеса, руль, ходовая часть, двигатель. Should Have — освещение ночью, сидения вместо стульев, двери и всё такое прочее. Could Have — автоматическая коробка передач и так далее. Таким же образом можно разобрать любой проект, где Must Have будет эдаким MVP.
Kano
Пример
Вы планируете делать следующие релизы и опрашиваете группу людей. Кто-то из них может сказать: «А вот вы там платную функцию сделали, из-за неё продукт стал хуже, фи!» Только потому, что она за деньги, эта функция покажется кому-то ненужной. Хотя для бизнеса это может быть ключевая вещь, которая приносит прибыль.





Классический метод приоритизации баг-листов
Критические багиКритичное юзабилити и забытые фичиНекритичные багиНекритичное юзабилитиТекстыХотелки / не будем делать / на усмотрение менеджера
Расчет надежности сервиса
Ваша система надежна настолько, насколько надежны её компоненты
Как описано в книге «Site Reliability Engineering: Надежность и безотказность как в Google» (далее — книга SRE), разработка продуктов и сервисов Google может достигать высокой скорости выпуска новых функций, сохраняя при этом агрессивные SLO (service-level objectives, цели уровня обслуживания) для обеспечения высокой надежности и быстрого реагирования. SLO требуют, чтобы сервис почти всегда был в исправном состоянии и почти всегда был быстрым. При этом SLO также указывают точные значения этого «почти всегда» для конкретного сервиса. SLO основаны на следующих наблюдениях:
В общем случае для любого программного сервиса или системы 100% — неверный ориентир для показателя надежности, поскольку ни один пользователь не сможет заметить разницу между 100%-ной и 99,999%-ной доступностью. Между пользователем и сервисом находится множество других систем (его ноутбук, домашний Wi-Fi, провайдер, электросеть…), и все эти системы в совокупности доступны не в 99,999% случаев, а гораздо реже. Поэтому разница между 99,999% и 100% теряется на фоне случайных факторов, обусловленных недоступностью других систем, и пользователь не получает никакой пользы от того, что мы потратили кучу сил, добиваясь этой последней доли процента доступности системы. Серьёзными исключениями из этого правила являются антиблокировочные системы управления тормозами и кардиостимуляторы!
Подробное обсуждение того, как SLO соотносятся со SLI (service-level indicators, индикаторы уровня обслуживания) и SLA (service-level agreements, соглашения об уровне обслуживания), смотрите в главе «Целевой уровень качества обслуживания» книги SRE. В этой главе также подробно описывается, как выбрать метрики, имеющие значение для конкретного сервиса или системы, что, в свою очередь, определяет выбор соответствующего SLO для этого сервиса или системы.
Эта статья расширяет тему SLO, чтобы сосредоточиться на составных частях сервисов. В частности, мы рассмотрим, как надежность критических компонентов влияет на надежность сервиса, а также как проектировать системы так, чтобы смягчить влияние или сократить количество критически важных компонентов.
Большинство сервисов, предлагаемых Google, направлены на обеспечение 99,99-процентной (иногда называемой «четыре девятки») доступности для пользователей. Для некоторых сервисов в пользовательском соглашении указывается более низкое число, однако внутри компании сохраняются целевые 99.99%. Эта более высокая планка дает преимущество в ситуациях, когда пользователи высказывают недовольство производительностью сервиса задолго до случая нарушения условий соглашения, поскольку цель № 1 команды SRE состоит в том, чтобы пользователи были довольны сервисами. Для многих сервисов внутренняя цель 99,99% представляет собой «золотую середину», которая уравновешивает стоимость, сложность и надежность. Для некоторых других, в частности глобальных облачных сервисов, внутренняя цель составляет 99,999%.
Хаб открытых данных – это …[править]
Основной независимый ресурс наборов открытых государственных данных, на котором собраны и структурированы существующие на сегодня в России наборы данных.+
Открытый ресурс, в который выгружают персональные данные граждан с целью продажи и передачи третьим лицам
В терминологии специалистов – историческое событие, после которого было открыто, что можно использовать данные в управлении процессами (продажи, менеджмент и т.д.)
Аналитическая панель, наглядное представление информации о бизнес-процессах, трендах, зависимостях и других метриках в компактном виде, которое позволяет увидеть значения конкретных показателей и динамику их изменений
Способ защиты данных с помощью визуальных решений
Алгоритм определения глобального приоритета
Частота (Frequency) проблемы прямым образом влияет на приоритет. Приоритет (Priority) и серьезность (Severity) прямым образом влияют на глобальный приоритет (Global Severity) дефекта: , где . Глобальный приоритет (globalSeverity) определяем по следующему алгоритму:
1. Первоначально изолировано от других факторов определяем серьезность дефекта (Blocker, Critical, Minor, Trivial).
2. Независимо от серьезности, определяем приоритет дефекта (High, Medium, Low).
3. Независимо от серьезности и приоритета, определяем частоту дефекта (High, Medium, Low, Very low).
4. Далее рассчитываем влияние частоты на первоначально определенный приоритет:
| Частота | Изменение приоритета |
| High | Medium —> HighLow —> Medium |
| Medium | Low —> Medium |
| Low | не изменяется |
| Very low | не изменяется |
5. Наконец, рассчитываем глобальный приоритет:
| Приоритет/Серьезность | Blocker | Critical | Minor | Trivial |
| High | Critical | Critical | Minor | Trivial |
| Medium | Critical | Critical | Minor | Trivial |
| Low | Trivial | Trivial |
— Critical — обязательно к исправлению. Сдача проекта не возможна с наличием данных дефектов.— Minor — допустимо в небольшом количестве. Сдача проекта не желательна с наличием данных дефектов, однако возможна с некоторым их наличием.— Trivial — сдача проекта возможна с наличием данных дефектов.







Надежность 99.99%: наблюдения и выводы
Давайте рассмотрим несколько ключевых наблюдений и выводов о проектировании и эксплуатации сервиса с надежностью 99,99%, а затем перейдем к практике.
Наблюдение № 1: Причины сбоев
Сбои происходят по двум основным причинам: проблемы с самим сервисом и проблемы с критическими компонентами сервиса. Критический компонент — это компонент, который в случае сбоя вызывает соответствующий сбой в работе всего сервиса.
Наблюдение № 2: Математика надежности
Надежность зависит от частоты и продолжительности простоев. Она измеряется через:
- Частоту простоя, или обратную от нее: MTTF (mean time to failure, среднее время безотказной работы).
- Продолжительность простоя, MTTR (mean time to repair, среднее время восстановления). Продолжительность простоя определяется временем пользователя: от начала неисправности до возобновления нормальной работы сервиса.
Таким образом, надежность математически определяется как MTTF/(MTTF+MTTR), используя соответствующие единицы измерения.
Вывод № 1: Правило дополнительных девяток
Сервис не может быть надежнее всех его критических компонентов вместе взятых. Если ваш сервис стремится обеспечить доступность на уровне 99,99%, то все критические составные части должны быть доступны значительно больше, чем 99,99% времени.
Внутри Google мы используем следующее эмпирическое правило: критические компоненты должны обеспечивать дополнительные девятки по сравнению с заявленной надёжностью вашего сервиса — в примере выше 99,999-процентную доступность — потому что любой сервис будет иметь несколько критических компонентов, а также свои собственные специфические проблемы. Это называется «правилом дополнительных девяток».
Если у вас есть критический компонент, который не обеспечивает достаточно девяток (относительно распространенная проблема!), вы должны минимизировать отрицательные последствия.
Вывод № 2: Математика частоты, времени обнаружения и времени восстановления
Сервис не может быть надежнее, чем произведение частоты инцидентов на время обнаружения и восстановления. Например, три полных отключения в год по 20 минут приводят в общей сложности к 60 минутам простоя. Даже если бы сервис работал отлично в остальное время года, 99,99-процентная надежность (не более 53 минут простоя в год) стала бы невозможной.
Это простое математическое наблюдение, но его часто упускают из виду.
Заключение из выводов № 1 и № 2
Если уровень надежности, на который полагается ваш сервис, не может быть достигнут, необходимо предпринять усилия для исправления ситуации — либо путем повышения уровня доступности службы, либо путем минимизации отрицательных последствий, как описано выше. Снижение ожиданий (т. е., объявленной надежности) тоже вариант, и зачастую — самый верный: дайте понять зависимому от вас сервису, что он должен либо перестроить свою систему, чтобы компенсировать погрешность в надежности вашей службы, либо сократить свои собственные цели уровня обслуживания. Если вы сами не устраните несоответствие, достаточно длительный выход системы из строя неизбежно потребует корректировок.
Вывод: рычаги для увеличения надежности сервиса
Стоит внимательно посмотреть на представленные цифры, потому что они подчеркивают фундаментальный момент: есть три основных рычага, для увеличения надежности сервиса.
- Сократите частоту отключений — за счет политик выпуска, тестирования, периодических оценок структуры проекта и т.д.
- Уменьшите уровень среднего простоя — с помощью сегментирования, географического изолирования, постепенной деградации, или изолирования клиентов.
- Сократите время восстановления — с помощью мониторинга, спасательных действий «одной кнопкой» (например, откат к предыдущему состоянию или добавление резервной мощности), практики оперативной готовности и т. д.
Вы можете балансировать между этими тремя методами для упрощения реализации отказоустойчивости. Например, если трудно достичь 17-минутного MTTR, сосредоточьте свои усилия на сокращении времени среднего простоя. Стратегии минимизации отрицательных последствий и смягчения влияния критических компонентов рассматриваются более подробно далее в этой статье.