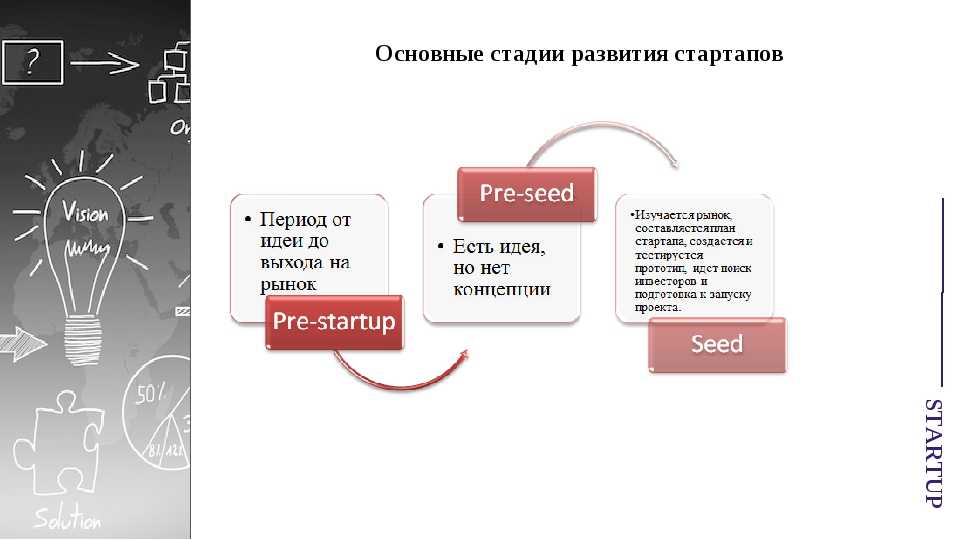
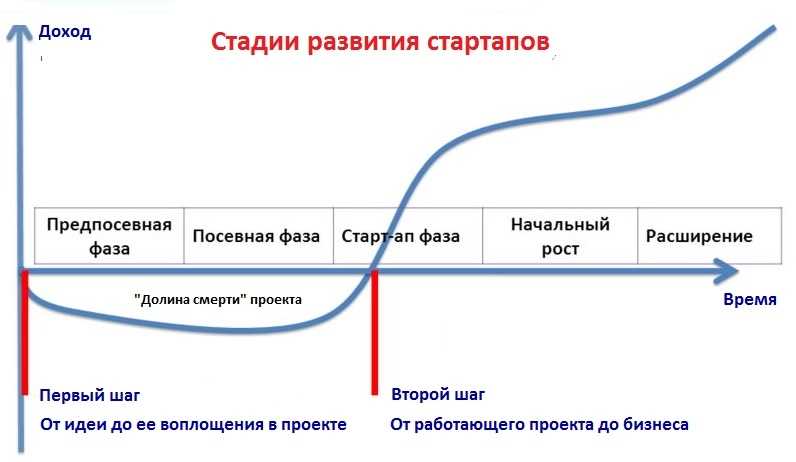
Введение: зачем понадобилось расширять команду
За несколько лет активной работы мы устаканили видение продукта, поняли, как именно он должен выглядеть хотя бы на текущий момент – понятно, что все может меняться. Мы разобрались с тем, кто наши клиенты, какие у них боли и проблемы – то есть нащупали, как говорят в США, product/market fit.
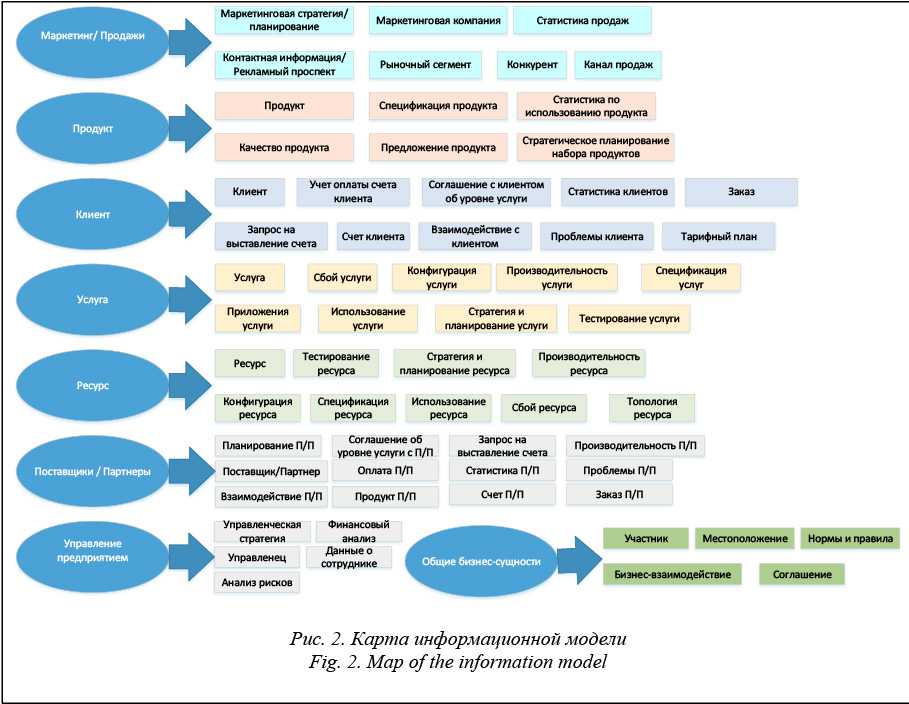
В частности, стало ясно, что наша модель – это all-in-one-product, то есть мы хотим сделать систему, которая покрывает все бизнес-процессы пользователей разных ролей внутри индустрии переводов. Здесь есть и заказчики, которым нужно как-то получить перевод, и компании-поставщики таких услуг, а есть конечные исполнители, которые переводят контент. Мы хотим автоматизировать работу каждого участника этой цепочки.
При этом под капотом:
-
извлечение переводимого текста из файлов офисных форматов,
-
куча ассинхронных операций, выполняемых на процессинге – расчет статистики, поиск глоссарных терминов, индексация миллионов unitов из баз переводов,
-
маркетплейс переводчиков (их умный подбор, тестирование и ранжирование внутри конкретного аккаунта),
-
поддержка мультиюзерного сценария работы внутри CAT-системы,
-
система биллинга и инвойсирования, работающая в интеграции с разными платежными провайдерами),
-
и т.п.
И все эти компоненты должны работать в тесной связке друг с другом и без перебоев, ведь в нашей системе каждый день работают более десяти тысяч пользователей с очень разными сценариями. Плюс каждое из направлений мы хотим активно развивать. В общем задач и возможностей всегда больше, чем ресурсов, и без расширения команды их не решить.
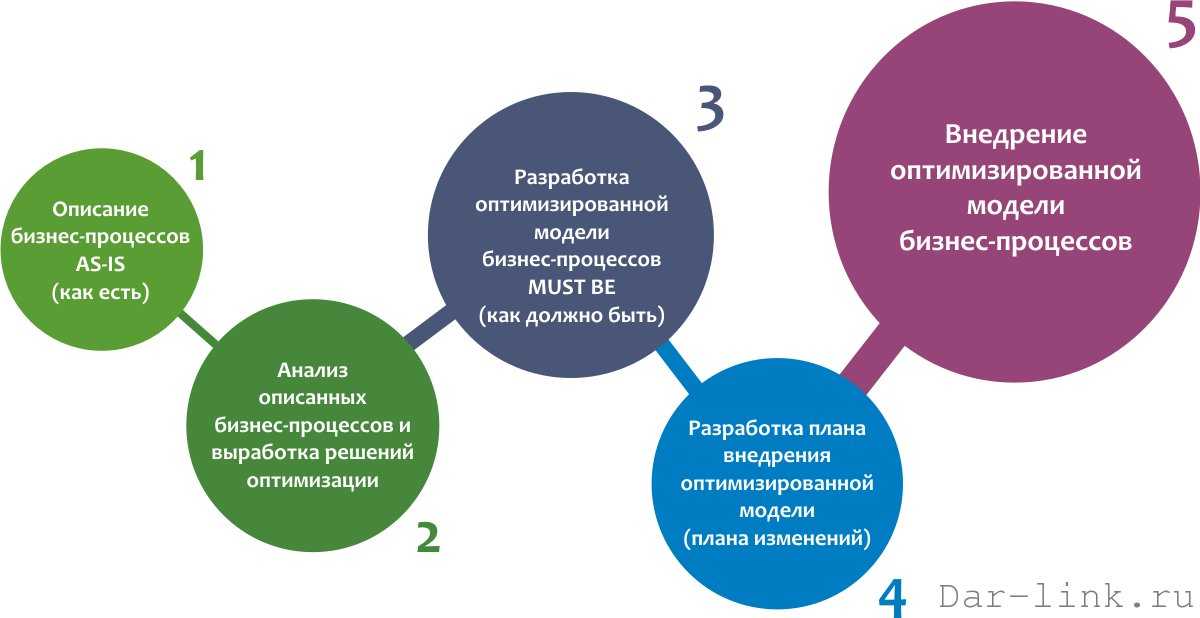
Процесс поиска и найма новых людей в стартап как раз может быть совсем непростым, постоянно подкидывать трудности. Вот, чему мы научились в ходе различных попыток решить эту задачу.
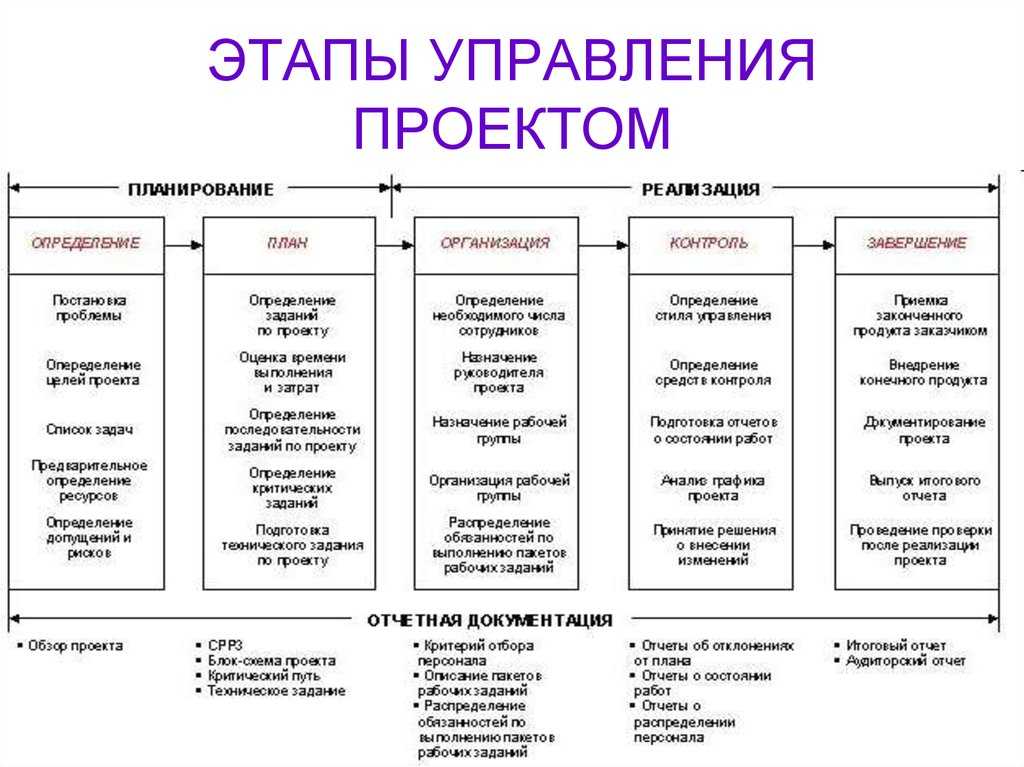
Запуск расширения
Двойной щелчок на имени расширения в окне из Рис.1, открывает окно расширения (Рис.3)
Рис.3
Как видим, оно представляет собой дерево, подобное дереву основной конфигурации. И здесь возникает один вопрос, в каких случаях следует заимствовать объект?
Необходимо заимствовать только те объекты, (справочники, документы, реквизиты и т.д.) которые будут использоваться в расширении формы, или в коде его модуля и без заимствования которых может появиться ошибка в работе расширения.
То есть, если для нашей разработки потребуется реквизит «ИНН» справочника «Физические лица», если он будет использован в модуле формы, мы должны его заимствовать из основной базы. В этом случае каждый раз при запуске расширения будет производиться проверка на наличие этого реквизита в справочнике основной конфигурации и на соответствие типа данных в исходной базе и в расширении.


Если после обновления или в ходе разработки нового функционала возникнет несогласованность между типами данных расширения и конфигурации или еще какие-то ошибки система проинформирует об этом пользователя (Рис.4)
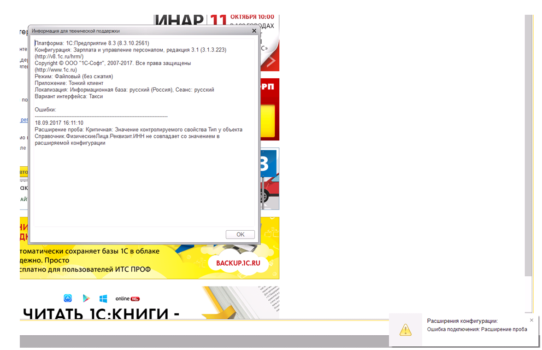
Рис.4
Окно в правом нижнем углу указывает на нестандартную ситуации при подключении расширения, двойной клик на нем открывает подробную информацию. В данном случае мы просто поменяли тип значения у реквизита ИНН со значения «Строка» на значение «Булево» у заимствованного объекта, однако гораздо чаще бывает обратная ситуация – когда обновление типового продукта приводит к изменению или ликвидации реквизита основной базы.
Отработав и протестировав расширение на копии базы, его можно выгрузить в отдельный файл, для этого в окне (Рис.5) необходимо нажать кнопку «Конфигурация», выбрать пункт «Сохранить в файл». В отличие от обычных файлов конфигурации, имеющих расширение cf, файл дополнения к конфигурации будет иметь маску *.cfe.
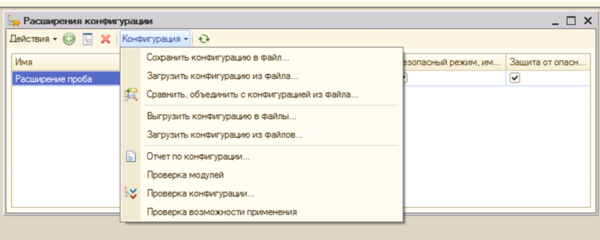
Рис.5
Как видно из вышеприведенного рисунка загрузить новый функционал можно из того же окна, а можно из основного окна программы.
Путь для подключения доработки выглядит следующим образом: Все функции->Стандартные->Управление расширениями конфигурации. Открывающееся окно представлено на Рис.6
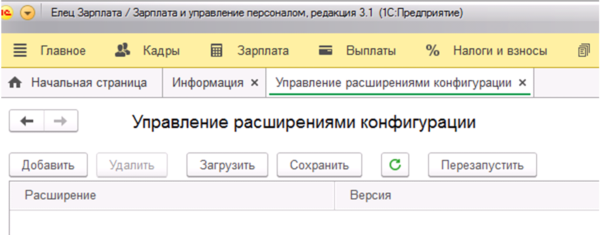 Рис.6
Рис.6
Нажатие на кнопку «Добавить», открывает диалоговое окно выбора файла, в котором необходимо выбрать нашу выгрузку. Если у обработки установлена галочка (Рис.7) и расширение содержит ошибку, подключение функционала будет отменено, и программа сообщит о возникновении исключительной ситуации.
 Рис.7
Рис.7
Чтобы после успешного добавления наш функционал заработал, программу надо перезапустить.
Методические рекомендации
9.2. Рекомендации по разработке
- При разработке расширения конфигурации рекомендуется применять версию платформы «1С:Предприятие 8» и версию конфигурации прикладного решения, используемые в сервисе.
- Используйте программный интерфейс БСП и прикладных конфигураций. При этом вам не придется переписывать код расширения конфигурации каждый раз после обновления типовых конфигураций.
- Если расширение конфигурации содержит формы, «выдерживайте» их в стиле конфигурации, для которой разработано расширение. Например, если в конфигурации принято команду «Записать и закрыть» располагать в верхней части формы, не размещайте ее в нижней части формы расширения конфигурации.
- Имена расширений конфигурации должны быть уникальными. Присваивайте расширениям конфигурации имена, которые не совпадут с именами, которые могут использовать другие разработчики расширений конфигурации.
9.3. О копировании кода из типовой конфигурации
- Если в типовой конфигурации есть готовая функция, которую можно вызвать, копировать ее в расширение конфигурации не нужно.
-
Если код, который есть в типовой конфигурации, подходит не полностью, очень осмотрительно подходите к вопросу копирования существующего кода:
- при обнаружении и исправлении ошибки в скопированном коде эта ошибка у пользователей расширения конфигурации не будет исправлена. В этом случае ответственность за своевременное исправление ошибок для пользователей вы берете на себя;
- по мере развития конфигурации ранее скопированный код может испортить данные пользователей.
9.4. Работа с базой данных
- При связанном изменении нескольких элементов данных, которое должно происходить атомарно, используйте транзакции.
- При изменении данных, которые могут редактироваться пользователями параллельно с выполнением расширения конфигурации, устанавливайте объектные блокировки.
9.5. Работа в веб-клиенте
- Если действия на сервере могут выполняться продолжительное время, используйте механизм длительных операций БСП. В противном случае приложение может закрыться по ошибке таймаута веб-сервера.
- Если расширение конфигурации могут использоваться при работе в веб-клиенте, то все ключевые возможности расширения конфигурации должны быть доступны пользователям без использования расширения работы с файлами.
9.6. О безопасности данных пользователя
-
Не предоставляйте конечному пользователю такие расширения конфигурации, с помощью которых он сможет испортить данные в своем приложении. Примеры:
- универсальные «перенумераторы» и «перепрефиксаторы»;
- поиск и замена значений;
- универсальные редакторы значений реквизита;
- удаление помеченных объектов без контроля ссылочной целостности.
- Желательно четко ограничивать функциональность расширений конфигурации, которые меняют данные пользователя. Например, если пользователю нужно перенумеровать кассовые документы, сделайте расширение конфигурации, которая будет делать именно это, без лишней универсальности.
У Вас задваивание безналичных платежей в УТ 11.4, исправляем!!!
Всем привет. Может такое произойти, что в окне безналичных платежей конфигурации УТ 11 происходит задвоение информации, т.е. от одного и того же контрагента пришли поступления одной и той же суммой в один и тот же день (дублирование). У меня данные из клиент-банка заливаются в БП, а затем через обмен выполняется перелив с БП в УТ, вот и получилось у меня задвоение. В журнале операций все прошло нормально, без задвоений, а вот в самой программе отобразилось уже так, произойти это могло по многим причинам (коряво прошел обмен, ошибка релиза, внутренние ошибки алгоритма и т.п. — вариантов масса).
Что я сделал, в первую очередь, конечно, резервную копию.
Строим графы средствами 1С (без GraphViz)
Множество статей на Инфостарте описывают, как работать с компонентой GraphViz, чтобы построить ориентированный граф. Но практически нет материалов, как работать с такими графами средствами 1С. Сегодня я расскажу, как красиво строить графы с минимальным пересечением.
Нам этот метод пригодился для отрисовки алгоритмов в БИТ.Финансе, т.к. типовой механизм не устраивал. Еще это может быть полезно для визуализации различных зависимостей: расчета себестоимости, графы аффилированности компаний и т.д.
Надеюсь, эта статья поможет сделать мир 1С красивее и гармоничней:)
Итак, поехали…

Что такое DTO (Data Transfer Object)?
Зачастую, в клиент-серверных приложениях, данные на клиенте (слой представления) и на сервере (слой предметной области) структурируются по-разному. На стороне сервера это дает нам возможность комфортно хранить данные в базе данных или оптимизировать использование данных в угоду производительности, в то же время заниматься “user-friendly” отображением данных на клиенте, и, для серверной части, нужно найти способ как переводить данные из одного формата в другой. Конечно, существуют и другие архитектуры приложений, но мы остановимся на текущей в качестве упрощения. DTO-подобные объекты могут использоваться между любыми двумя слоями представления данных.
DTO — это так называемый value-object на стороне сервера, который хранит данные, используемые в слое представления. Мы разделим DTO на те, что мы используем при запросе (Request) и на те, что мы возвращаем в качестве ответа сервера (Response). В нашем случае, они автоматически сериализуются и десериализуются фреймворком Spring.
Представим, что у нас есть endpoint и DTO для запроса и ответа:
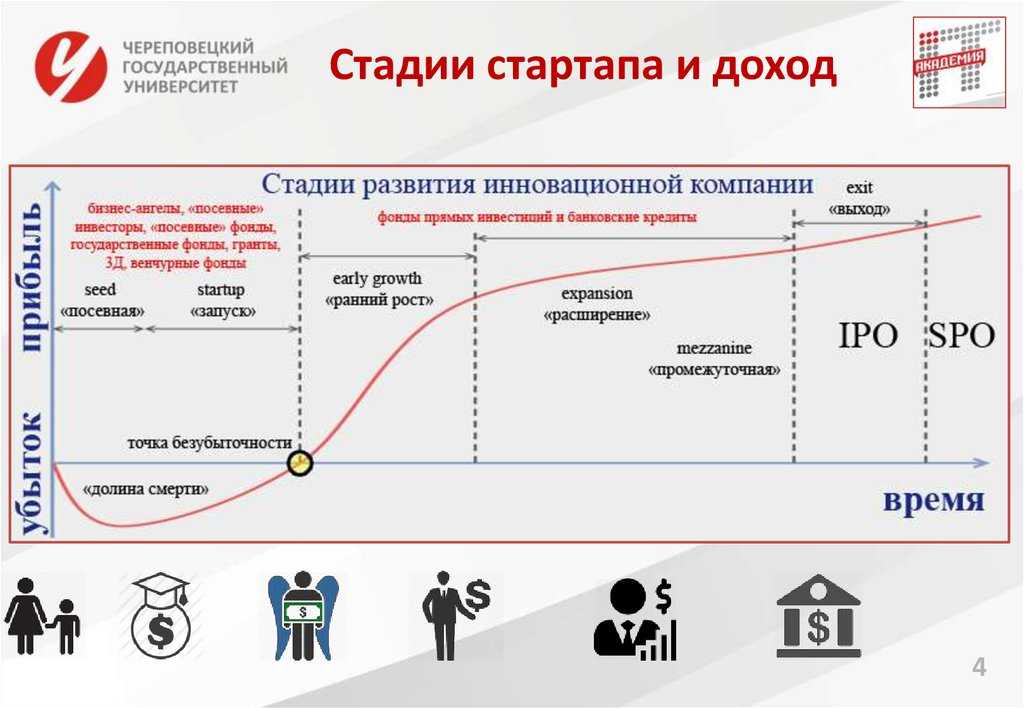
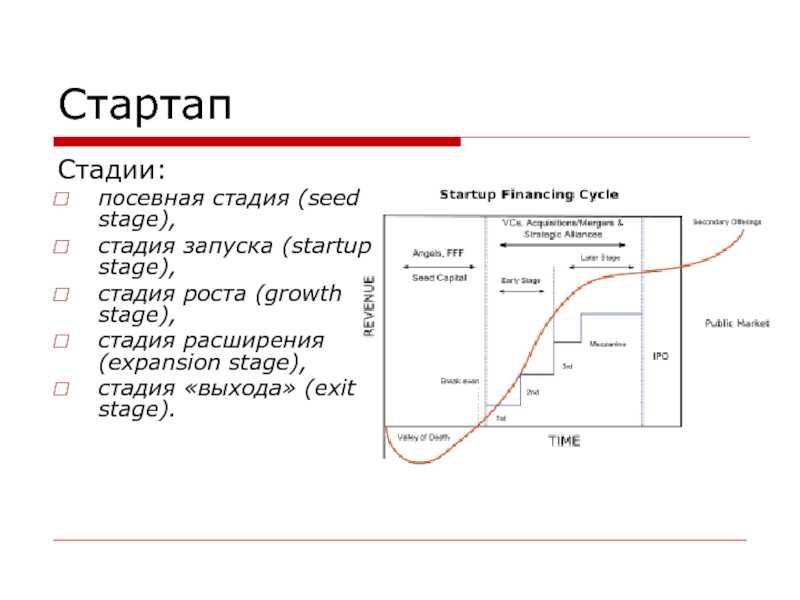
Урок #1: структура внутри команды не должна ограничивать рост
Когда мы начинали, в команде было порядка 15 разработчиков, то есть это был классический стартап. Все ответственные за все, продукт был небольшим, видение его будущего было еще не сформировано, мы его искали. В той реальности лучше работала схема максимальной взаимозаменяемости, когда каждый инженер мог взять любую часть продукта и понять, что с ней делать, внести изменения или протестировать.
Мы работали по гибридной модели «скрамбана» (по крайней мере, мы так на тот момент называли этого монстра): был какой-никакой релизный цикл, бэклог, продакты, чья воля транслировалась через аналитиков, был менеджер, распределяющий задачи программистам.
От этой модели при расширении команды пришлось отказаться по ряду причин:
-
звено менеджера стало бутылочным горлышком, bus factor начал зашкаливать;
-
выросло количество запросов к системе / пожеланий от пользователей;
-
наблюдалась потеря информации в узлах передачи информации от клиента к разработчиками;
-
сформировалось понимание продукта, на которое не ложилась текущая схема работы, продукт большой, и все не могут разбираться во всем, слишком разные процессы. Да и “все за все» – не есть структура, давайте не будем забывать про знаменитый знаменитый закон Конвея.
Начали думать, как изменять модель, чтобы победить все эти сложности. В итоге (ничего нового я вам не открою) пришли к тому самому Scrum-процессу. Каждая команда отвечает за один из элементов цепочки – продукт для заказчиков перевода, сервис-провайдеров или конечных исполнителей, задачи дробятся в рамках этих направлений (платежи, подбор исполнителей, отчетность и т.п.) Такую систему можно без проблем масштабировать и адаптировать под потребности бизнеса, да и потери и TTM (Time To Market) там меньше.Одним из важных шагов на пути прихода к такому сетапу стала книжка Hyper Growth, если бы знала о ней раньше – могли бы пройти некоторые шаги и сделать открытия гораздо быстрее. В общем, да, рекомендую к прочтению всем IT-менеджерам, потом не забудьте сказать мне спасибо за 70 листов отборной полезной информации.
Иные форматы
Помимо STIX и MISP, больших китов в мире стандартизации обмена данными threat intelligence, есть немало иных форматов. И надо сказать, что наибольшее количество опенсорных фидов — в форматах txt и csv. Редко, когда можно найти их в STIX или MISP, которые я бы назвал, скорее, уделом коммерческих, отмодерированных, обогащенных, хорошо структурированных фидов. Иные форматы (MAEC, IODEF, CAPEC, IODEF, VERIS) — редкость.
Почему же стали настолько популярны txt и csv? Ответ один — из-за простоты. Большинство опенсорсных фидов — это либо фиды с минимальным контекстом (временные метки, именования вредоносного ПО, теги), либо просто голые индикаторы компрометации без какого-либо контекста (только значения индикаторов). Наиболее простой способ упаковки таких индикаторов — plain text или csv, так как любые иные форматы имеют более высокий порог входа.
Минус фидов в plain-text — отсутствие контекста, то есть обычно такие фиды — это листы IP-адресов, хешей, доменов, URL, реже — чего-то иного. Проблема в том, что таким фидам без контекста, «голым» по-сути, сложно доверять и интерпретировать, так как не понятно, что за угрозы представляют содержащиеся в них индикаторы компрометации, и насколько эти угрозы актуальны и вредоносны.
Фиды в csv часто содержат несколько колонок, описывающих значения, тип индикатора, временные метки. Иногда встречаются описания вредоносного ПО или эксплуатируемых уязвимостей, которые связаны с этим индикатором. В общем случае фиды в csv, где есть хоть какой-то контекст, могут быть полезнее. Однако это зависит от различных ситуаций, ведь может случиться так, что plain-text фид с индикаторами по очень актуальной угрозе для конкретной отрасли или компании может оказаться полезнее любого другого фида с контекстом.
Основные проблемы при работе с фидами в таких свободных форматах, как txt и csv, — это сбор и приведение к единой нормальной форме, а также связывание данных. Txt может содержать комментарии, в одном файле могут находиться разные фиды и использоваться различные способы разделения индикаторов компрометации — такие фиды достаточно сложно парсить. В csv-фидах порядочную сложность также порой представляет извлечение данных: разделители в одном файле могут не быть консистентными. Это актуально для фидов, где правки делаются вручную, да и вообще наша практика показала, что нежданчик может случиться в любой момент. Отдельная тема — это неявность связи атрибутов в csv. Иногда довольно сложно понять, какие атрибуты к чему относятся.

Примеры
В этом примере явно видно, что есть одна колонка с индикатором компрометации, одна колонка с семейством вредоносного ПО, которая связана с хешем, есть колонка со страной (хотя не вполне понятно, страна — это источник атаки или цель), есть колонка со ссылкой на исследование/отчет по угрозе. Такой csv-фид более-менее понятен.
Вот другой пример фида с однозначным и хорошим описанием — понятно, какие есть атрибуты и какие между ними имеются взаимосвязи:
А вот в этом примере не понятно, к чему относится дата: к третьей колонке (URL) или к пятой (хеш)?
Еще один пример: есть две колонки с индикатором компрометации (url, ip), есть колонка с датой — и непонятно, к какому из индикаторов компрометации эта дата относится, а также, что она означает. Время первого обнаружения индикатора? Время последнего обнаружения индикатора? Что-то иное?
Как видно из примеров, форматы общего назначения вполне подходят для публикации фидов TI, но проблема обычно кроется в последующей интерпретации этих форматов. Это может вносить существенную путаницу при использовании данных в процессе применения TI, например, при реагировании на инциденты. В этом отношении специализированные STIX/MISP решают проблему интерпретации гораздо лучше из-за детерминированности схем данных.
За бортом обсуждения также остаются немногочисленные практики публикации фидов в устаревших форматах, например, STIX 1.*, OpenIOC и иных — они действительно либо безнадежно устарели и более не используются, либо слились с другими стандартами, либо эволюционировали в более новые версии, отвечающие нынешним запросам.
Немного теории
До появления механизма расширений процесс обновления типовых конфигураций в значительной степени зависел от того, находится ли конфигурация на поддержке или в нее внесены изменения. В последнем случае, разработчику приходилось:
- Сравнивать типовую и имеющуюся структуру метаданных;
- В случае существенного отличия типовых элементов следить за корректным обновлением;
- Вносить соответствующие изменения после обновления.
Все это сильно усложняло процесс обновления, увеличивая время отработки и, зачастую, лишало организацию возможности обновления типовых модулей дорогостоящего программного обеспечения.
Механизм расширений позволяет без снятия типовой конфигурации с поддержки дорабатывать многие ее элементы. Фактически, разработчик, на основе типового решения создает свою собственную конфигурацию, которая является оболочкой для типового решения. В этом случае процесс обновления типовой части происходит автоматически, при запуске же конечным пользователем платформа объединяет оба решения для пользователя.
Собственные структуры данных
Одна из первых задач любого внедрения — адаптация структуры хранимых данных к реалиям конкретного проекта, то есть расширение структуры данных.
С версии 8.3.11 платформа умеет через расширения создавать справочники, документы, регистры сведений. С 8.3.13 — РН, РБ, РР, полноценные планы обмена, ПВХ, ПС, ПР.
Эти возможности широко применялись на проекте для расширения структуры данных. Расширялся реквизитный состав заимствованных справочников и документов, добавлялись собственные документы, регистры сведений, регистры накопления. Более того, на смежном проекте внедрения решения 1С:ERP в той же компании проектная команда решила не использовать дополнительные реквизиты вообще. В итоге для описания всей специфики номенклатуры в едином расширении было создано более 100 новых реквизитов, десяток перечислений и справочников-классификаторов. Результат по производительности не ставит каких-либо значимых вопросов, все работает так же быстро, как и типовая ERP.
Работать с расширенной структурой данных удобно. Она поддерживается конструктором запросов и в пользовательском режиме, и в конфигураторе.

Однако стоит учитывать ряд особенностей:
1. Тип ЛюбаяСсылка не содержит ссылок на собственные типы расширения. Механизмы, использующие этот тип, с данными расширения работать не будут.
2. Если в заимствованный справочник/документ добавлен новый реквизит, необходимо захватить в расширение роль, дающую права на этот справочник/документ, иначе реквизит останется без прав и не будет показан на форме.
Что делают хорошие DTO?
Во-первых, очень важно понимать, что вы не обязаны использовать DTO. Это прежде всего паттерн и ваш код может работать отлично и без него
- Если вы используете одно представление данных на оба слоя, вы вполне можете использовать ваши сущности в качестве DTO.
- Если вы хотите вручную заниматься сериализацией ваших сущностей в JSON, то я не могу вас остановить!
Они также помогают документировать слой представления в человеко читаемом виде. Мне нравится использовать DTO и, я думаю, вы тоже могли бы их использовать, ведь это к тому же способствует уменьшению зацепления (decoupling) между слоем представления и предметным слоем, позволяя приложению быть более гибким и уменьшая сложность его дальнейшей разработки.
Тем не менее, не все DTO являются хорошими. Хорошие DTO помогают создавать API согласно лучшим практикам и в соответствии с принципам чистого кода.
Они должны позволять разработчикам писать API, которое внутренне согласовано. Описание параметра на одной из конечных точек (endpoint) должно применяться и к параметрам с тем же именем на всех связанных точках. В качестве примера, возьмём вышепредставленный фрагмент кода. Если поле price при запросе определено как “цена с НДС”, то и в ответе определение поля price не должно измениться. Согласованное API предотвращает ошибки, которые могли возникнуть из-за различий между конечными точками, и в то же время облегчает введение новых разработчиков в проект.
DTO должны быть надёжными и сводить к минимуму необходимость в написании шаблонного кода. Если при написании DTO легко допустить ошибку, то вам нужно прилагать дополнительные усилия, чтобы ваше API оставалось согласованным. DTO должны “легко читаться”, ведь даже если у нас есть хорошее описание данных из слоя представления — оно будет бесполезно, если его тяжело найти.
Давайте посмотрим на примеры DTO, а потом определим, соответствуют ли они нашим требованиям.
Заимствование объектов и порядок срабатывания модулей
Для того, чтобы проследить последовательность выполнения обработчиков, мы включим возможность изменения нашей конфигурации и добавим в нее новую обработку, функционал которой будет заключаться только в одном – она будет сообщать, что её запустили из основной конфигурации, код на Рис.8.
 Рис.8
Рис.8
Добавим эту обработку в расширение.
Для этого:
Правой кнопкой мышки активизируем контекстное меню формы обработки (Рис.9);
 Рис.9
Рис.9
- Выберем пункт «Добавить в расширение»;
- В дереве дополнительной конфигурации появится и сама обработка и дубликат её формы;
- Открыв форму, мы обнаруживаем, что команда, вызывающая сообщение тоже есть, только ей не присвоен обработчик;
- Добавление действия команды вызывает диалоговое окно (Рис.10) в котором помимо основных директив места исполнения команды, присутствуют еще группа «Тип вызова».
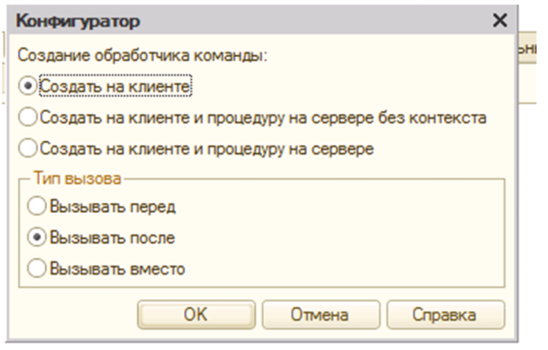 Рис.10
Рис.10
Мы имеем три типа вызова для имеющейся процедуры;
- Вызывать перед – исполнение кода расширения будет запущено прежде, чем отработает основная конфигурация;
- Вызывать после – доработанная процедура пойдет вторым номером;
- Вызывать вместо – процедура из основной конфигурации вообще не будет выполнена.
Оставим тип вызова в положении «Вызывать после» и добавим процедуру «Расш1_СообщитьПосле(Команда)» (Рис.11).


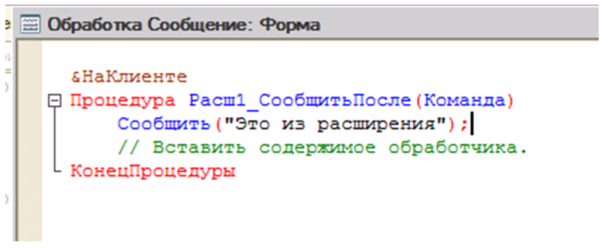 Рис.11
Рис.11
Результатом запуска нашей обработки будет последовательно сообщенные две фразы (Рис.12), то есть сообщение дополнительной конфигурации отобразиться после сообщения основной. В случае если бы мы выбрали «Вместо», первой строки мы бы вообще не увидели.
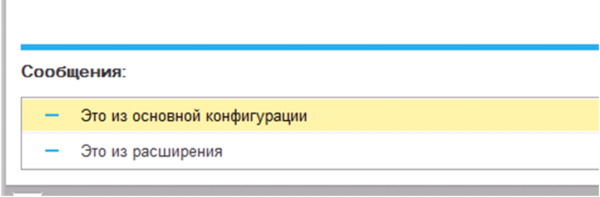 Рис.12
Рис.12
Начиная с версии 8.3.9.1818, в функционал программы был включен механизм изменения типовых модулей, а так же добавления собственных модулей. И здесь перед разработчиками стояла вполне конкретная задача: как определить, в каком порядке должны выполняться заимствованные процедуры и функции не только по отношению к основной конфигурации, но и по отношению к уже подключенным в конфигурации расширениям.
Хранение новых реквизитов
Рассмотрим способ реализации хранения данных в расширении. Под новые справочники и документы создаются новые таблицы. Они помечаются суффиксом Х и порядковым номером. Например, Reference789X1.
Когда в заимствованный объект расширения добавляется новый реквизит, табличная часть или реквизит табличной части, в базе данных копируется весь набор таблиц объекта с теми же суффиксами в названиях. Например, для таблицы справочника Reference34 будет создана Reference34X1, для новой табличной части может быть создана таблица Reference34_VN34437X1.
Таблицы нового набора дополняются созданными в расширении структурами, после чего данные переносятся в новые таблицы. Дальше вся работа идет с этими таблицами в рамках разделителей текущей области.
Если расширение после изменения основной конфигурации не может быть запущено, оно переводится в неактивный режим. Новые данные не удаляются и не теряются. Для отключения расширения необходимо выбрать соответствующий пункт меню и подтвердить свои намерения в диалоге. Случайно это сделать сложно, поэтому опасения, которые возникли, когда возможность только появилась, сейчас напрасны.
Есть особенность в работе глобального метода ПолучитьСтруктуруХраненияБазыДанных(): в именах таблиц не показываются суффиксы, поэтому определить этим методом наличие или отсутствие расширенной структуры невозможно.
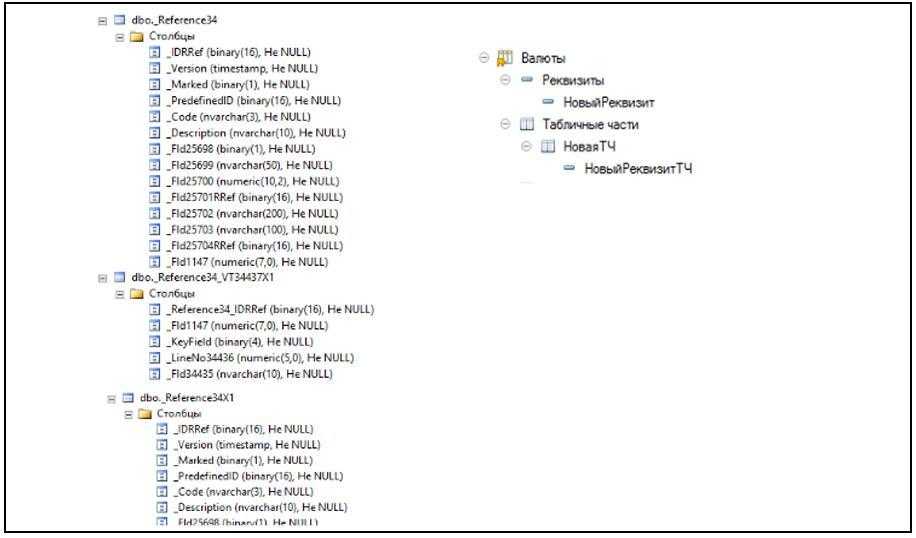
На иллюстрации приведен пример, как выглядит расширенная структура данных для заимствованного справочника расширения, в которую добавлены новый реквизит и новая табличная часть. Видим, что созданы копия таблицы с суффиксом X1 и таблица для табличной части, в конце которой тоже суффикс. Все данные справочника перенесены в новую таблицу.
Во второй части статьи о расширениях поговорим о РН, изменении режима совместимости, доработке модулей и форм, отчетах и печатных формах.



