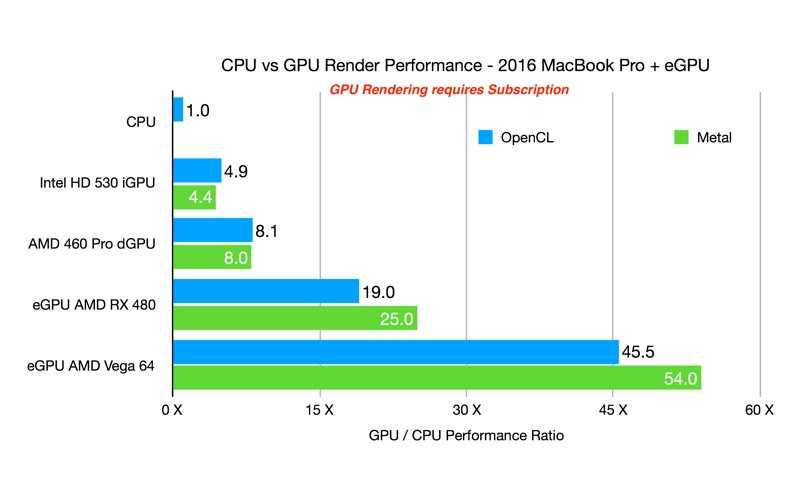
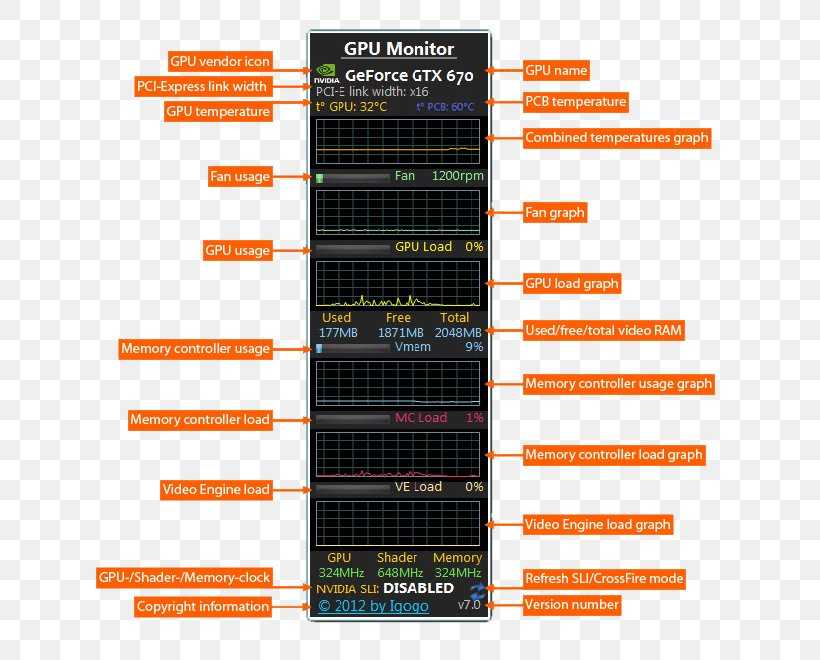
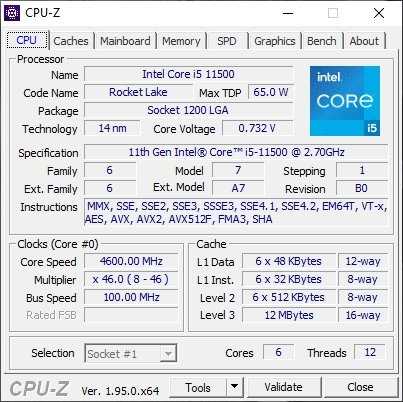
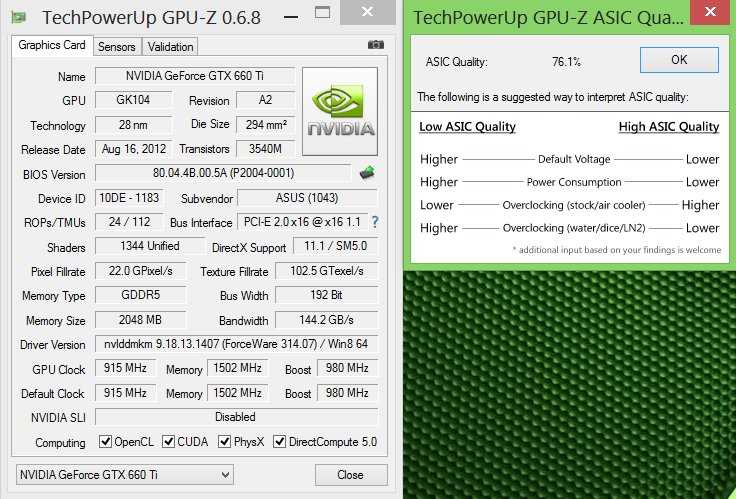
Особенности работы Intel Core i5-11500
Core i5-11500 является наиболее интересным процессором из пары тестируемых CPU. И причина не только в более высокой частоте Turbo Boost, но и в самом характере работы Core i5-11500 из коробки. Производитель задекларировал для Core i5-11500 базовую частоту 2.70 ГГц, чтобы процессор мог вписаться в теплопакет 65 Вт. При этом максимальная тактовая частота при однопоточной нагрузке для Core i5-11500 составляет внушительные 4.60 ГГц. Что касается нагрузки всех шести ядер CPU, то в этом случае они будут работать на частоте 4.20 ГГц.
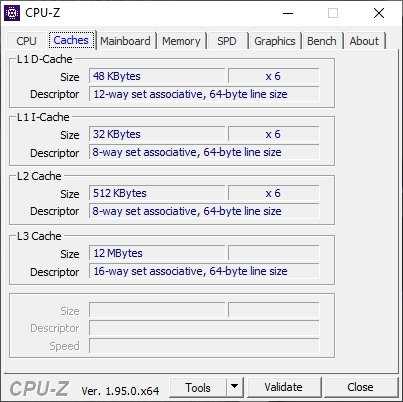
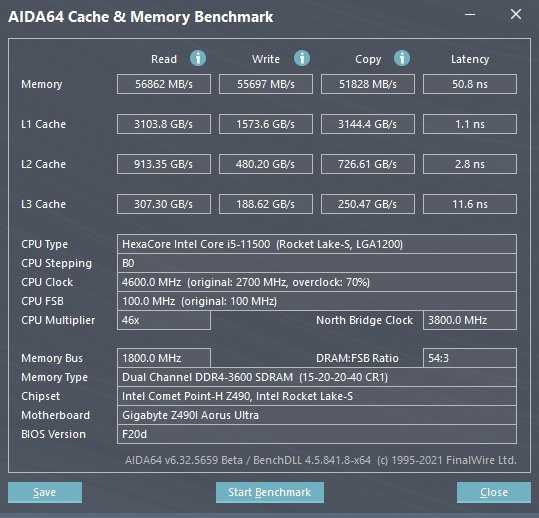
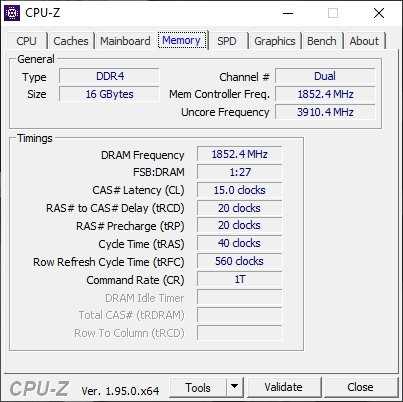
Если говорить о разгоне оперативной памяти, то в этом отношении Core i5-11500 позволяет настроить одноранговые модули 2х8 Гб в режиме DDR4-3600. Разумеется с сохранением синхронного режима работы ОЗУ и контроллера памяти. Для стабильности на этих частотах напряжение на системный агент Core i5-11500 приходится поднимать до разумных 1.30 В.
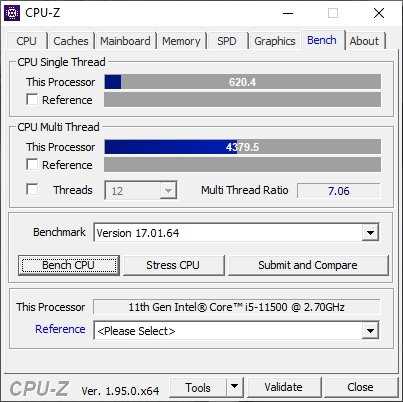
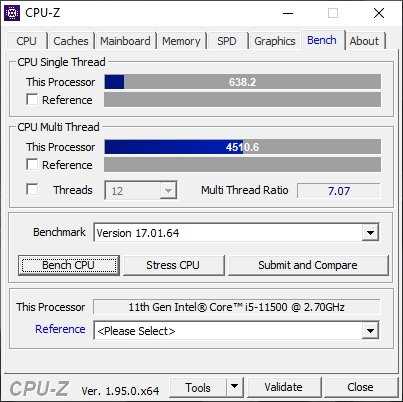
Однопоточная производительность Core i5-11500 из коробки впечатляет. Во встроенном тесте CPU-Z новый шестиядерный Rocket Lake набирает более 620 баллов.
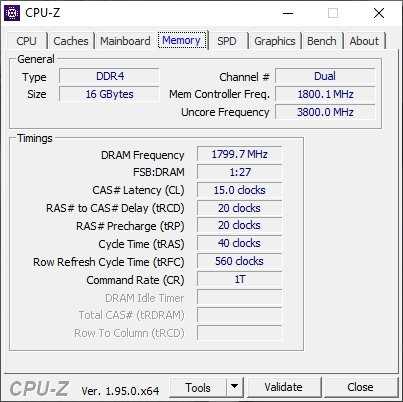
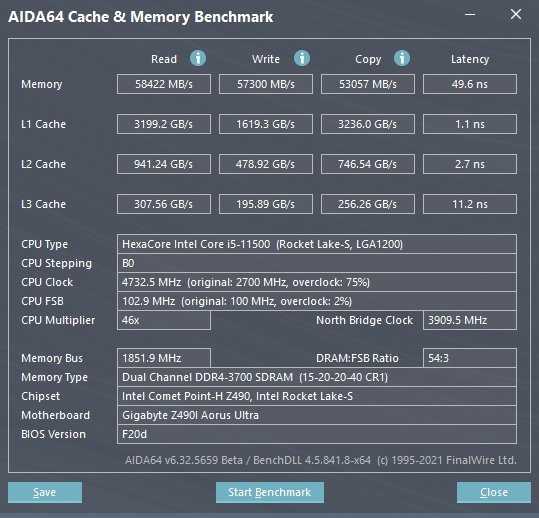
С новым контроллером памяти, которым обладают процессоры семейства Rocket Lake, изменились и показатели производительности ОЗУ. В сравнении с процессорами предыдущих поколений новые CPU демонстрируют более скромные задержки, в чем немного напоминают процессоры из конкурентного лагеря. В режиме Gear1 DDR4-3600 с процессором Core i5-11500 удается получить солидные значения пропускной способности памяти и латентность в районе 50 нс. Перевод контроллера ОЗУ в режим Gear2 позволяет памяти ускориться до DDR4-4533. На системе с процессором Core i5-11500 это увеличивает пропускную способность до впечатляющих значений. Но асинхронная работа контроллера памяти и ОЗУ неизбежно накладывают штраф в виде сильно увеличившейся латентности.
Несмотря на заблокированный множитель, у Core i5-11500 остается возможность разгона по шине. Ее, пусть и в скромных значениях, но удается поднять до частоты 102.90 МГц. Это позволяет Core i5-11500 работать на максимальной тактовой частоте 4733 МГц при загрузке одного ядра и на 4322 МГц при загрузке всех шести ядер. После разгона процессор набирает в однопоточном тесте CPU-Z внушительные 638 баллов.
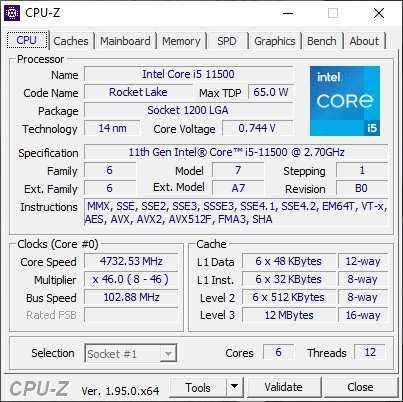
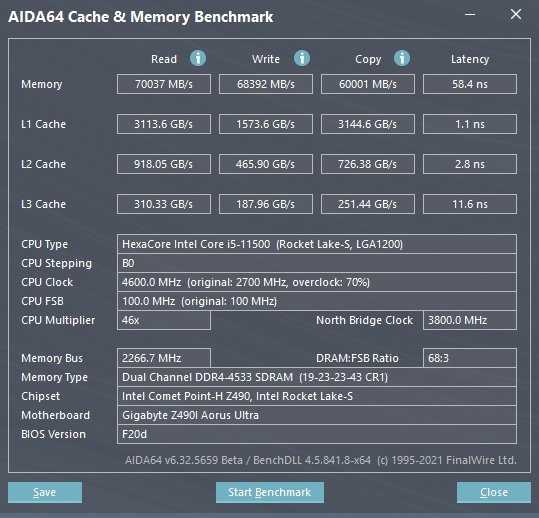
Разгон Core i5-11500 по шине до 102.90 МГц позволяет увеличить синхронно частоты контроллера памяти и самой ОЗУ до режима работы DDR4-3700. В этом случае системе удается снизить задержки ниже психологической планки в 50 нс. Увеличение частоты положительно влияет и на показатели пропускной способности памяти.
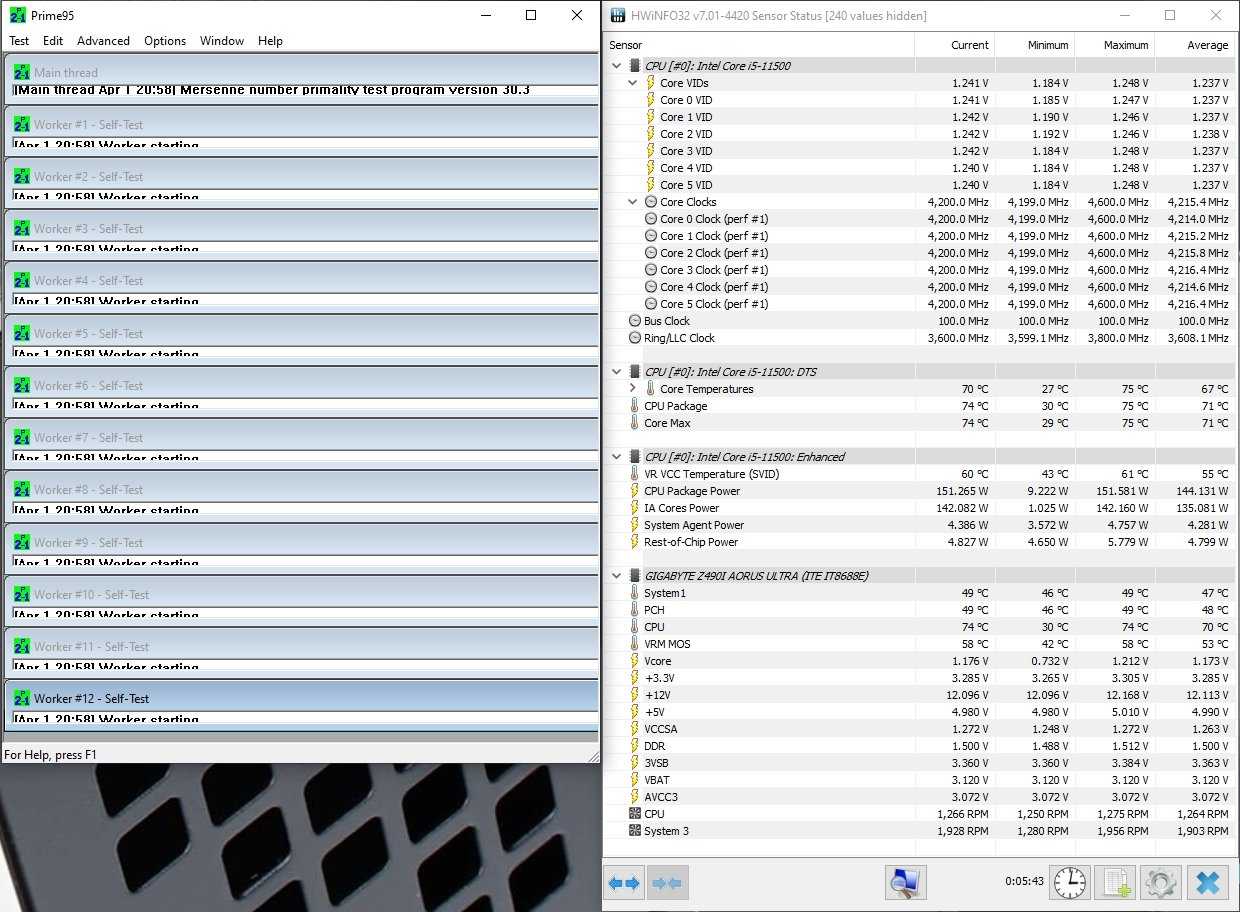
Немаловажными моментами в работе процессоров Rocket Lake являются энергопотребление и нагрев новых CPU. Учитывая наличие инструкций AVX-512 у процессоров Intel Core 11-поколения, мы рассмотрели характер работы этих процессоров в различных условиях. В случае с Core i5-11500 запускаем на 5 минут стресс-тест Prime95 с поддержкой AVX-512 и смотрим на пиковые значения при полной нагрузке. Процессор Core i5-11500 сохраняет работоспособность всех шести ядер на частоте 4.20 ГГц. При этом его энергопотребление составляет 151 Вт, а максимальная температура — 75 ℃.
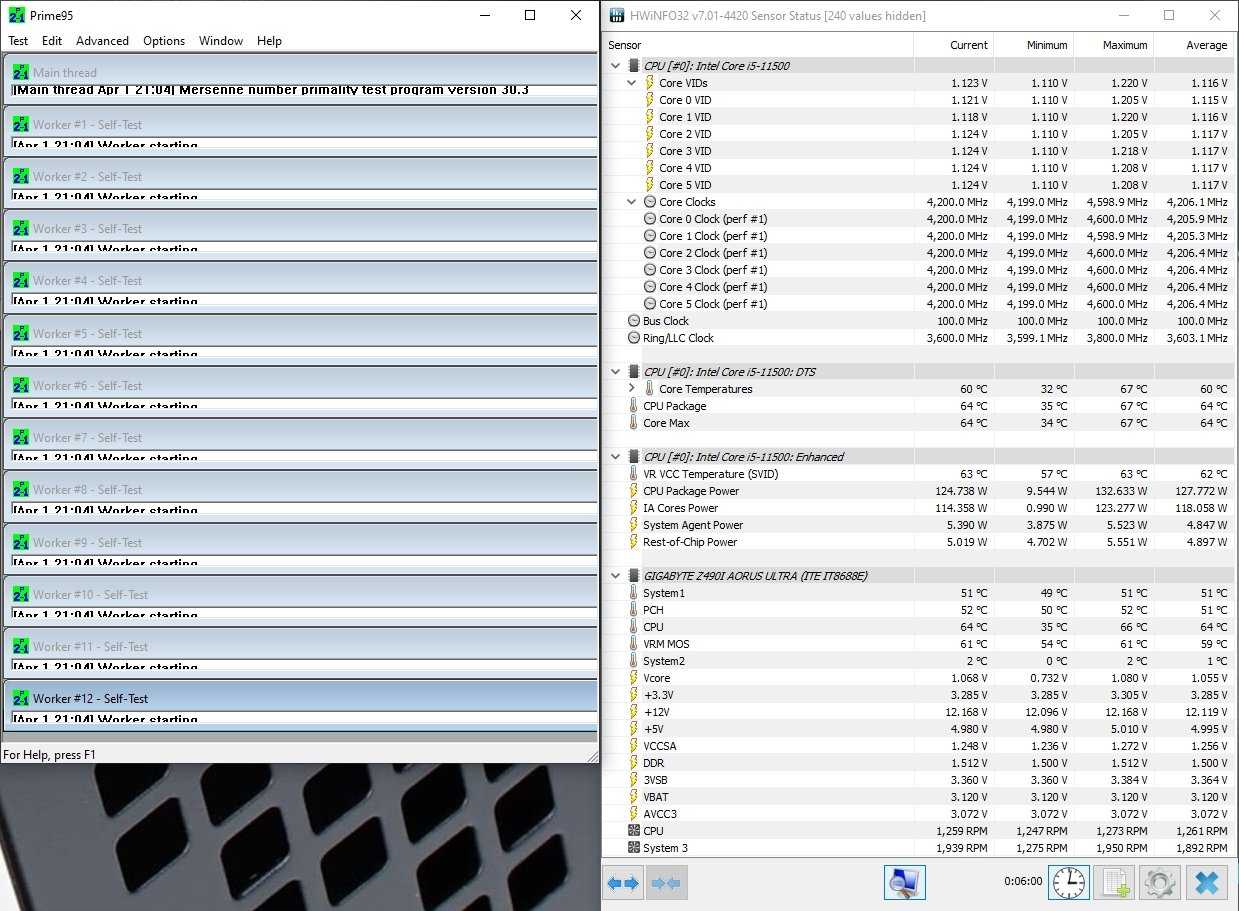
Тот же стресс-тест Prime95, но без задействованных инструкций AVX-512 позволяет Core i5-11500 чувствовать себя более комфортно. При максимальной частоте всех шести ядер 4.20 ГГц процессор ограничивается энергопотреблением в 132 Вт, нагреваясь при этом до 67 ℃.
Причина третья: никакой мишуры, только нужные технологии
AMD предпочитает не использовать проприетарные стандарты. Она двигает индустрию вперед, делая свои технологии доступными для всех.
Приведу отличный пример. Пару лет назад NVIDIA пыталась продвинуть свой G-Sync, продавая производителям специальные модули и лицензию на их использование. Как итог, стоимость мониторов с технологией динамического обновления возросла до небес. Но тут пришла AMD со своей Freesync. Она бесплатная, дешевая и не имеет ограничений. Как вы думаете, в чью пользу в итоге сделали выбор потребители? Покажу наглядно: зайдем на сайт одного из популярных сетевых магазинов, например «Ситилинк». Смотрим соотношение:
Как видим, мониторов с Freesync почти в 10 раз больше! В конце концов, NVIDIA сдалась и запилила в своих драйверах поддержку технологии конкурента, стыдливо назвав ее «G-Sync compatible».
Предисловие
Попытка сравнить производительность процессоров на разнородных архитектурах x86-64, e2k (Эльбрус), mips и arm.
Все тесты написаны на языке C (взяты из исходных кодов, которые я не модифицировал и не оптимизировал) и компилируются под конкретную архитектуру с использованием конкретного компилятора для данной архитектуры и тесты производятся на различных дистрибутивах операционных систем на ядре Linux. На результаты может влиять как тип так и версия компилятора, а также режим оптимизаций. Хотя даже таким способом можно примерно сравнить производительность процессоров на разных архитектурах.
P.S.: Знаю, что большинство тестов для очень старых компьютеров, но они работают везде. Что даже очень неплохо.
Тестовый стенд
| Процессор | Intel Core i5-11500 Intel Core i5-11400 |
| Материнская плата | Gigabyte Z490i Aorus Ultra (Bios F20d) |
| Видеокарта | Sapphire AMD Radeon RX 6800 XT 16Gb |
| Термоинтерфейс | Arctic MX-2 |
| Оперативная память | Goodram IRDM Pro Hollow White DDR4-4000 2*8Gb |
| Накопитель | M.2 SSD Samsung 970 Pro 512 Гб |
| Блок питания | Corsair RM850x мощностью 850 Вт |
| Кулер | A-Data XPG Levante 360 |
| Монитор | ASUS PB298Q, 29″, 2560×1080, IPS |
| Система | Windows 10 Pro 64-bit 20H2 |
Для тестирования процессоров Core i5-11500 и Core i5-11400 использовалась материнская плата Gigabyte Z490i Aorus Ultra с последним BIOS F20d с поддержкой Rocket Lake. В качестве оперативной памяти использовался комплект одноранговых модулей Goodram IRDM Pro Hollow White DDR4-4000 2*8Gb. Место графического адаптера заняла видеокарта Sapphire AMD Radeon RX 6800 XT 16Gb в референсном исполнении.
Для качественного охлаждения процессоров использовалась система жидкостного охлаждения A-Data XPG Levante 360. Тестирование выполнялось на открытом тестовом стенде, который выглядел следующим образом.


Тестовые стенды и их процессоры
Стенды на процессорах x86 (i386) х86-64 (amd64):
- Core i7-2600
- AMD A6-3650
- Atom Z8350
- Core 2 Duo T9400
- Core i7-4700MQ
- Core i3-m330
- Xeon 6128
- Pentium M725
- Pentium 4 3066
- Pentium III 1000
Стенды на процессорах armv6 (armel), armv7 (armhf), armv8 (aarch64):
- Odroid N2 (Amlogic S922X)
- Odroid X2 (Samsung Exynos 4412)
- Orange Pi PC2 (Allwinner H5)
- Orange Pi Win (Allwinner A64)
- Raspberry PI 3 (Broadcom BCM2837B0)
- Raspberry PI (Broadcom BCM2835)
- AWS Graviton (Alpine AL73400)
Стенды на процессорах e2k (Elbrus 2000) (v3, v4, v5):
- E8C-SWTX (Elbrus 8C)
- E8C-E8C4 (Elbrus 8C x4 cpu)
- E8C2 (Elbrus 8C2) (1200 MHz, 1550 MHz)
- E2S-EL2S4 (Elbrus 4C x4 cpu)
- E2S-PC401 (Elbrus 4C)
- MBE1C-PC (Elbrus 1C+)
Стенды на процессорах MIPS :
Таблица с тестовыми стендами
| Стенд | Модель процессора | Всего ядер (потоков) | Частота (МГц) | Архитектура |
|---|---|---|---|---|
| Xeon 6128 | Intel Xeon Gold 6128 CPU @ 3.40GHz (2 CPU) | 12 (6/12) | 3,400.00 | amd64 |
| Core i7-4700MQ | Intel Core(TM) i7-4700MQ CPU @ 2.40GHz | 8 (4/8) | 2,400.00 | amd64 |
| Core i7-2600 | Intel Core(TM) i7-2600 CPU @ 3.40GHz | 8 (4/8) | 3,400.00 | amd64 |
| Core 2 Duo T9400 | Intel Core(TM) 2 Duo CPU T9400 @ 2.53GHz | 2 | 2,530.00 | amd64 |
| Core i3-m330 | Intel Core(TM) i3 CPU M 330 @ 2.13GHz | 4 (2/4) | 2,133.00 | amd64 |
| Atom Z8350 | Intel Atom(TM) x5-Z8350 CPU @ 1.44GHz | 4 | 1,440.00 | amd64 |
| AMD A6-3650 | AMD A6-3650 APU with Radeon(tm) HD Graphics | 4 | 2,600.00 | amd64 |
| Pentium M725 | Intel Pentium(TM) M 725 @ 1600 | 1 | 1,600.00 | i386 |
| Pentium 4 | Intel Pentium(TM) 4 CPU | 1 | 3,066.00 | i386 |
| Pentium III | Intel Pentium(TM) III CPU | 1 | 1,000.00 | i386 |
| AWS Graviton | Alpine AL73400 | 16 | 2,300.00 | aarch64 |
| Odroid N2 | Amlogic S922X | 6 | 1,800.00 | aarch64 |
| Odroid X2 | Samsung Exynos 4412 (armv7l) | 4 | 1,700.00 | arm |
| Orange Pi PC2 | Allwinner H5 (aarch64) | 4 | 1,152.00 | aarch64 |
| Orange Pi Win | Allwinner A64 (aarch64) | 4 | 1,344.00 | aarch64 |
| Raspberry PI 3 | Broadcom BCM2837B0 (armv8) | 4 | 1,200.00 | aarch64 |
| Raspberry PI | Broadcom BCM2835 | 1 | 700.00 | arm |
| E16C-APPROX! | Elbrus 16 | 16 | 2,000.00 | e2k |
| E8C2-1550 | Elbrus 8C2 (E8C2) | 8 | 1,550.00 | e2k |
| E8C2-1200 | Elbrus 8C2 (E8C2) | 8 | 1,200.00 | e2k |
| E8C-SWTX | Elbrus 8C (E8C-SWTX) | 8 | 1,300.00 | e2k |
| E8C-E8C4 | Elbrus 8C (4 CPU) | 32 (8 x 4 cpu) | 1,300.00 | e2k |
| E2S-EL2S4 | Elbrus 4C (EL2S4) (4 CPU) | 16 (4 x 4 cpu) | 750.00 | e2k |
| E2S-PC401 | Elbrus 4C (E2S) (pc401) | 4 | 800.00 | e2k |
| MBE1C-PC | Elbrus 1C+ (MBE1C-PC) | 1 | 985.00 | e2k |
| Baikal T1 BFK | Baikal-T1 (MIPS P5600 V3.0) | 2 | 1,200.00 | mips |
Причина первая: цена
Политика компании, которая состоит в том, чтобы давать лучшие характеристики по доступной стоимости, очень мне близка. Я никогда не гнался за максимальной производительностью, а выбирал наилучшее соотношение цена/FPS.
Так уж повелось, что AMD практически всегда выигрывала по этому показателю у NVIDIA. Карты, которыми я владел (а это, например, Radeon HD 7870, R9 290, RX 5700) на момент покупки были более выгодным приобретением, чем аналоги GeForce.
Сейчас, в связи с бумом майнинга, цены стали неадекватными у обоих участников рынка. Правда, AMD пострадала больше. Посмотрим, что произойдет после анонса новой серии RX 6000 — по идее, старые поколения должны подешеветь.
Оценка производительности
- Пиковое значение производительности и пропускной способности памяти (теоретические): 2420 GFLOP/s в одинарной точности и 352 GB/s для Intel Xeon Phi 7120A; 1036 GFLOP/s в одинарной точности и 119 GB/s для 2 процессоров Intel Xeon E5-2697v2 с 1866 MHz DDR3 памятью.
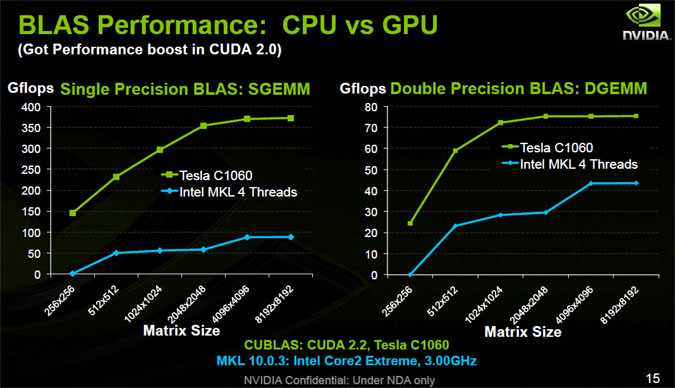
- Значения полученные на Linpack (или GEMM) and STREAM triad бенчмарках дают нам соответствующие показатели максимальной производительности на платформе: 2178 GFLOP/s и 200 GB/s для Intel Xeon Phi 7120A; 930 GFLOP/s и 100 GB/s для 2 процессоров Intel Xeon E5-2697v2 с 1866 MHz DDR3 памятью.
- Арифметическая интенсивность приложения рассчитывается на базе количества сложений и умножений (ADD, MUL) чисел с плавающей запятой и количества байт пересланных из памяти и определенной количеством загрузок и записей в память (LOAD, STORE).
Арифметическая интенсивность платформы
Арифметическая интенсивность вычислительного ядра
Список литературы
- D. Imbert, K. Immadouedine, P. Thierry, H. Chauris, and L. Borges, “Tips and tricks for finite difference and i/o-less fwi,” in Expanded Abstracts. Soc. Expl. Geophys., 2011, pp. 3174–3178.
- S. Williams, A. Waterman, and D. Patterson, “Roofline: an insightful visual performance model for multicore architectures,” Communications of the ACM — A Direct Path to Dependable Software, vol. 52, pp. 65–76, April 2009.
- J. Dongarra, P. Luszczek, and A. Petitet, “The linpack benchmark: past, present and future,” Concurrency and Computation: Practice and Experience, vol. 15, no. 9, pp. 803–820, 2003, doi:10.1002/cpe.728.
- J. D. McCalpin, “Stream: Sustainable memory bandwidth in high performance computers,” University of Virginia, Charlottesville, Virginia, Tech. Rep., 1991-2007, a continually updated technical report. www.cs.virginia.edu/stream
- L. Borges, “Experiences in developing seismic imaging code for Intel Xeon Phi coprocessor.”, 2012. software.intel.com/en-us/blogs/2012/10/26/experiences-in-developing-seismic-imaging-code-for-intel-xeon-phi-coprocessor
- J. H. Holland, “Genetic algorithms and the optimal allocation of trials,” SIAM Journal of Computing, vol. 2, no. 2, pp. 88–105, 1973.
II. Особенности алгоритмов быстрой обработки изображений
Для целей нашей статьи из всего многообразия алгоритмов быстрой обработки изображений мы возьмём только те, которые обладают такими характеристиками, как локальность, возможность распараллеливания и их относительная простота. Поясним более подробно, что мы имеем в виду:
- Локальность. Каждый пиксел вычисляется на основе ограниченного количества соседей.
- Высокая способность к распараллеливанию. Каждый пиксел не зависит по данным от других обработанных пикселей, что позволяет распараллелить процесс обработки.
- 16/32-битная точность арифметики. Как правило, при обработке изображений достаточно 32-битной вещественной (floating point) арифметики для обработки и 16-битного целочисленного типа данных для хранения.
1. Производительность
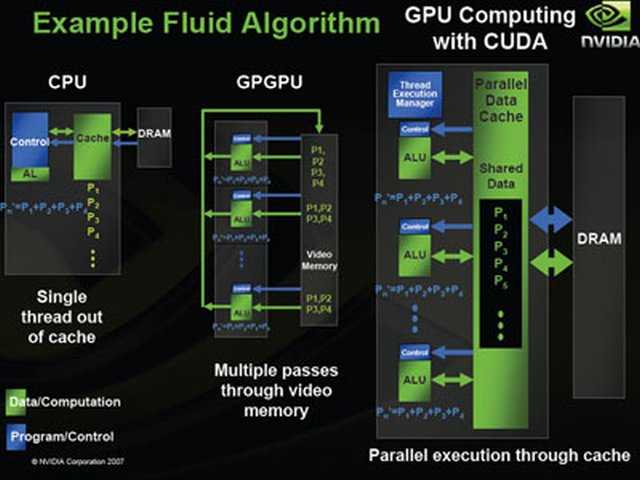
Как показывает практика, максимальной производительности можно добиться двумя способами — либо через увеличение аппаратных ресурсов, то есть с помощью наращивания количества процессоров, либо через оптимизацию программного кода. При сравнении возможностей графического процессора и центрального, в этом классе задач GPU выигрывает у CPU в соотношении цена/производительность, а реализация всего потенциала GPU возможна лишь при распараллеливании и тщательной многоуровневой оптимизации используемых алгоритмов.
2. Качество обработки изображений
Еще одним важным критерием является качество обработки изображений. Для одной и той же операции обработки изображений может существовать несколько алгоритмов, отличающихся ресурсоёмкостью и качеством получаемого результата
И тут важно понимать, что обычно ресурсоёмкие алгоритмы дают более качественный результат. Таким образом, многоуровневая оптимизация наиболее востребована для ресурсоёмких алгоритмов
После её выполнения сложные алгоритмы могут выдавать результат за приемлемое время, сравнимое со временем работы изначально быстрого, но более грубого алгоритма.
3. Латентность
Как уже говорилось выше, GPU имеет такую архитектуру, которая позволяет осуществлять параллельную обработку пикселов изображения, что приводит к сокращению латентности, или времени обработки одного изображения. Центральные процессоры обладают довольно скромными показателями латентности, поскольку в CPU параллелизм реализуется на уровне отдельных кадров, тайлов или строк изображений.
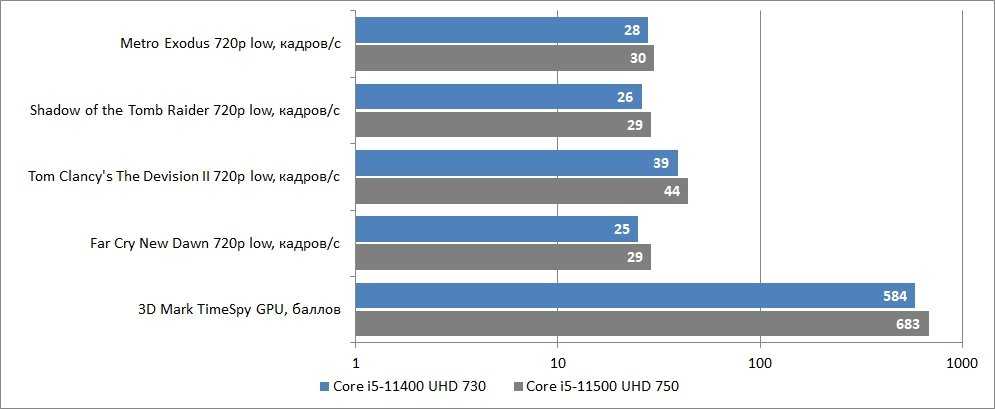
Сравнение встроенной графики UHD 730 и UHD 750
Не обошли вниманием и новую встроенную графику процессоров семейства Rocket Lake. Как мы знаем, Core i5-11400 оснащен графическим ядром UHD 730, в то время как Core i5-11500 имеет на борту более производительный чип UHD 750
Какова разница между этими графическими ядрами и насколько велика их производительность вообще, наглядно демонстрирует бенчмарк из AIDA64.
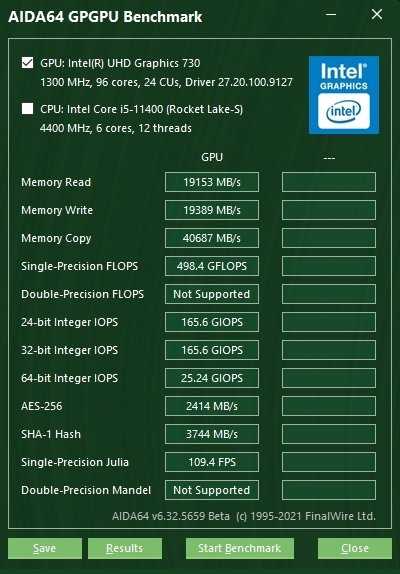
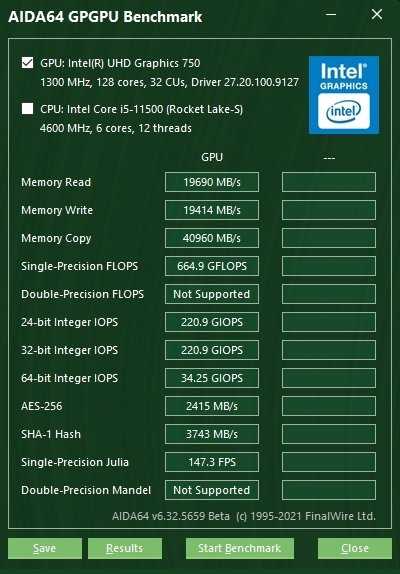
Также мы оценили производительность встроенной в процессоры графики на примере современных играх. Во всех игровых проектах использовалось разрешение 1280х720 точек и низкий пресет графики. Для закрепления результатов тестирования iGPU их производительность была оценена в тесте 3D Mark TimeSpy.
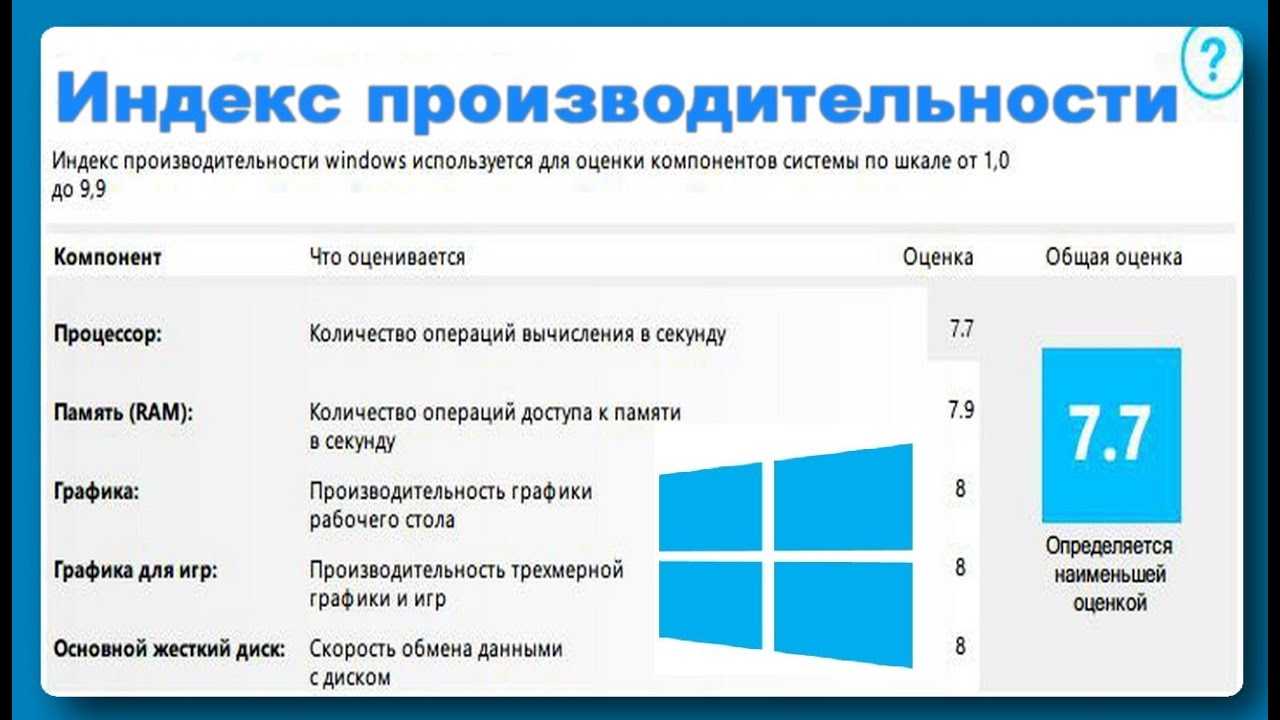
Что такое и для чего нужен индекс производительности
Необходимость использования средств для определения производительности компьютера появилась не вчера. Сухие характеристики вроде названия процессора, видеокарты и количества оперативной памяти ни о чем не говорят рядовому владельцу ПК.
Специально для тех, кто не может или не хочет вдаваться в технические особенности устройства, разработан коэффициент производительности.

Это оценка, которая выставляется по десятибалльной шкале на основе нескольких характеристик:
- процессор (количество вычислений в секунду);
- оперативная память (количество операций доступа к ОЗУ в секунду);
- видеокарта (производительность ПК в интерфейсе);
- видеокарта (производительность ПК в играх);
- жесткий диск (скорость передачи информации).
По каждому из указанных компонентов Windows 10 выставляет рейтинг от 1 до 10 баллов, из которого формируется общая оценка (это то, что касается встроенных средств определения индекса). Также пользователь может протестировать компьютер при помощи специальных программ. Но в таком случае допускается обращение к другим методологиям расчета. В зависимости от конкретной утилиты компьютер тоже набирает определенное количество баллов, но трактовка итогового результата зачастую отличается.



Важно
Анализируя стандартный индекс производительности, примите во внимание, что итоговая оценка – это не средний показатель по характеристикам, а минимальный балл в одной из категорий
Рабочая и игровая производительность
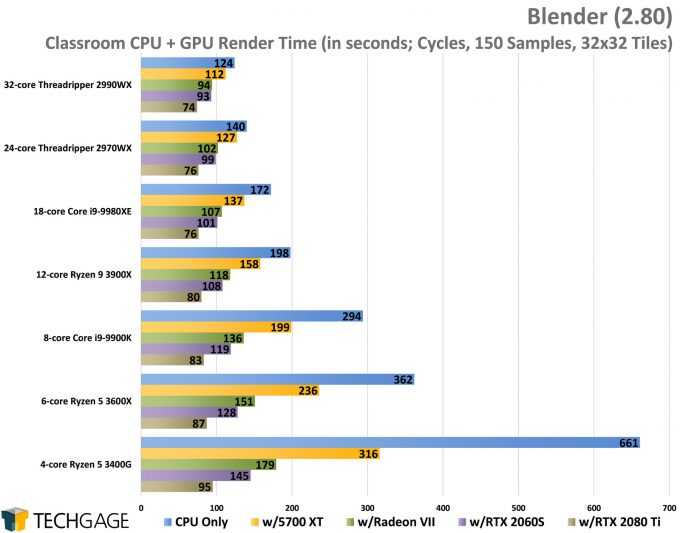
После того, как мы детально изучили характер работы обоих процессоров, возможности разгона ОЗУ и самих CPU непосредственно, посмотрим на итоговую производительность Core i5-11500 и Core i5-11400. Для этого мы использовали ряд синтетических бенчмарков, тестовых программ, а также несколько ресурсоемких игр. Полученные результаты представили в виде графиков, анализируя которые каждый читатель может почерпнуть для себя что-то полезное.
Производительность подсистемы оперативной памяти:
Комплексная производительность:
Рендеринг:
Видеомонтаж:
Архивация данных:
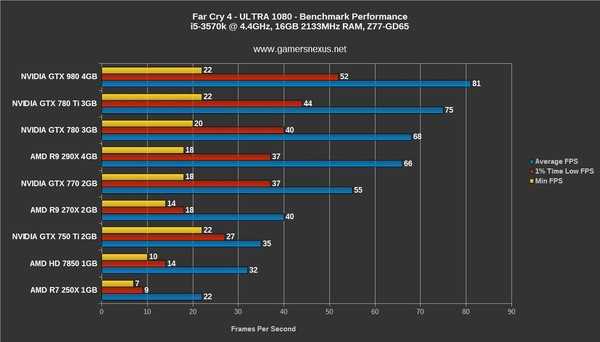
Игровая производительность:
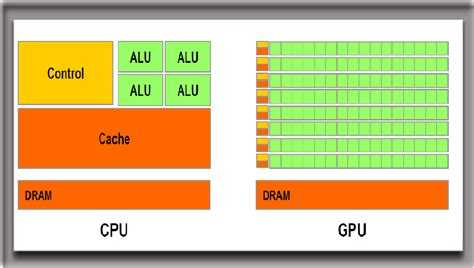
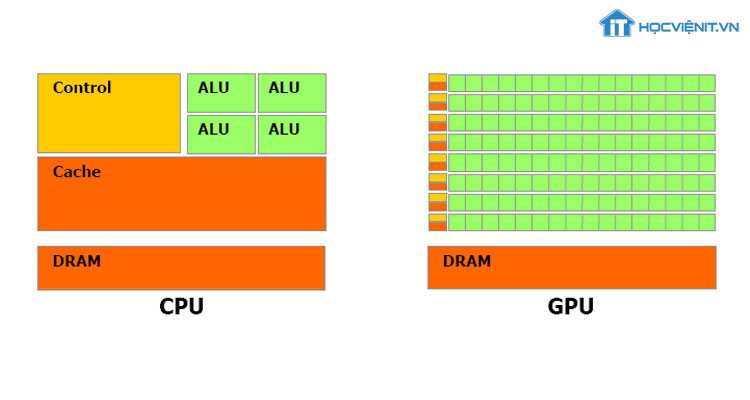
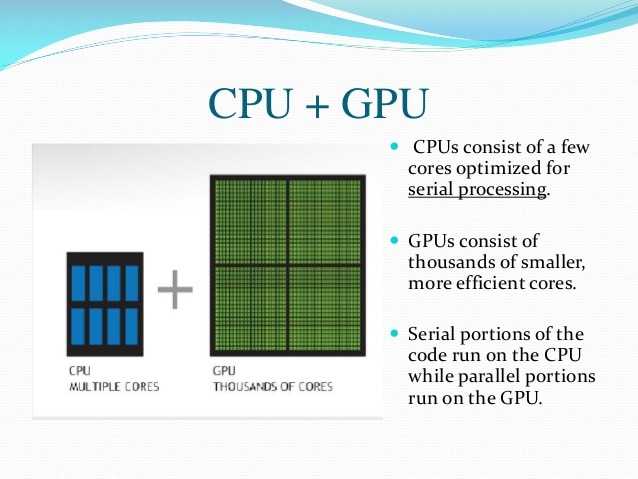
IV. Преимущества GPU над CPU
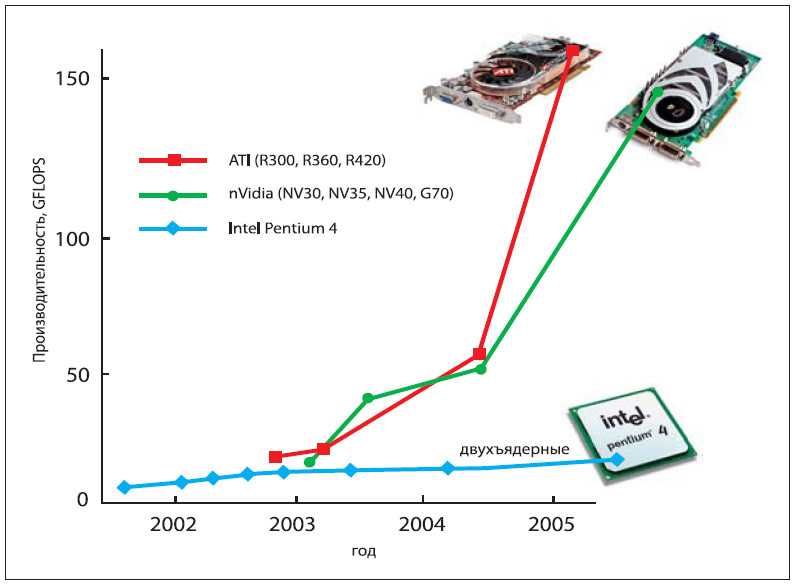
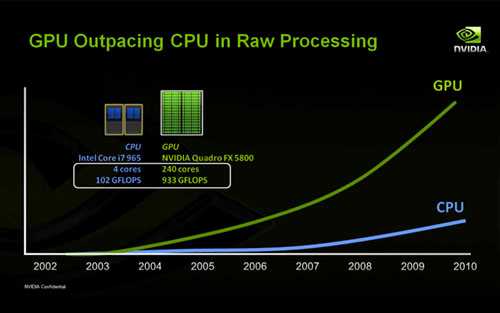
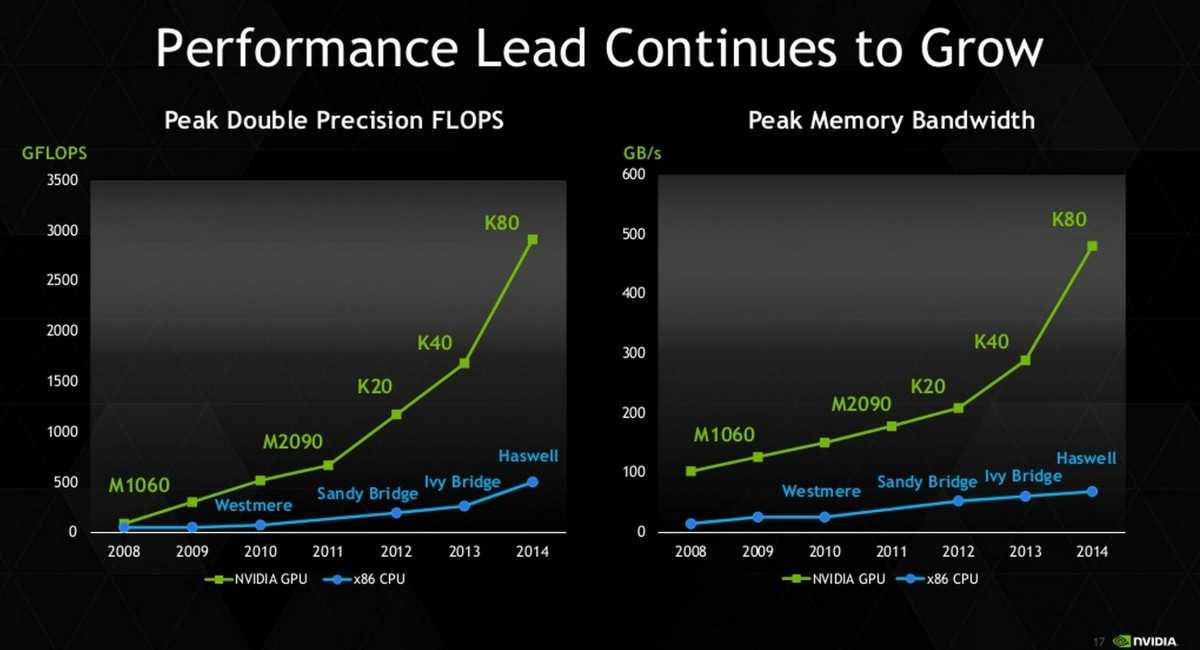
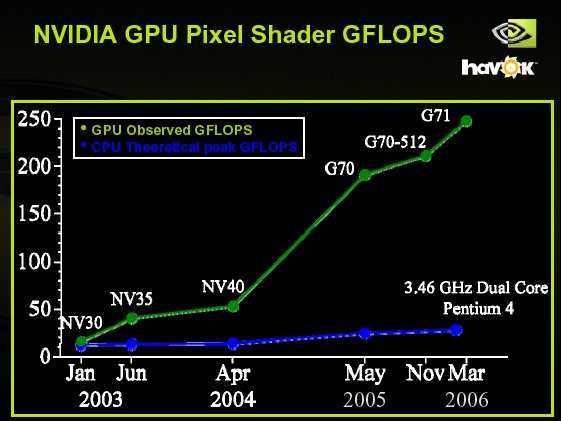
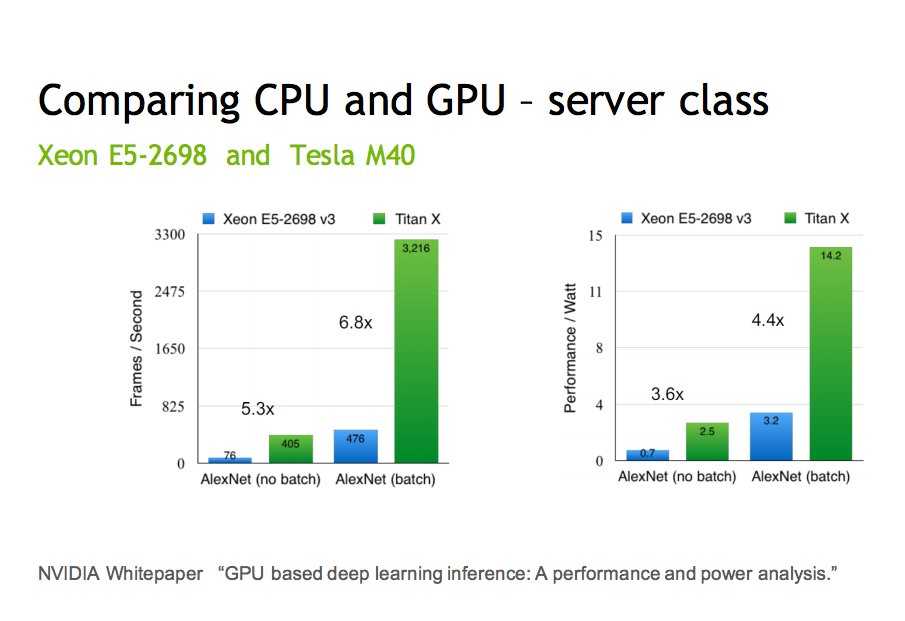
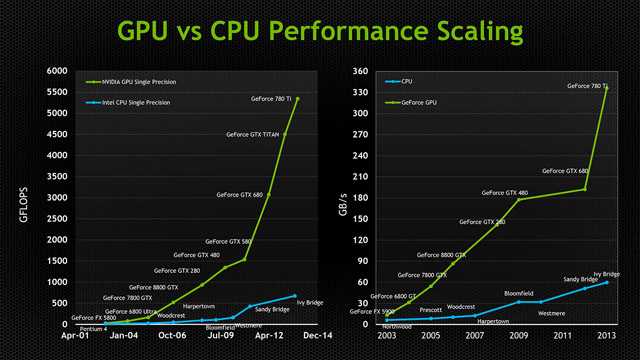
Наши лабораторные исследования показали, что при сравнении идеально оптимизированного софта для GPU и для CPU (с применением AVX2), преимущество GPU имеет глобальный характер: пиковые производительности CPU и GPU аналогичного года производства отличаются обычно на порядок для 32- и 16-битных типов данных. Также на порядок отличается и пропускная способность подсистемы памяти. В следующих пунктах мы рассмотрим эту ситуацию подробнее.
Если же использовать для сравнения софт для CPU без использования инструкций AVX2, то разница в производительности может достигать 50-100 раз в пользу GPU.
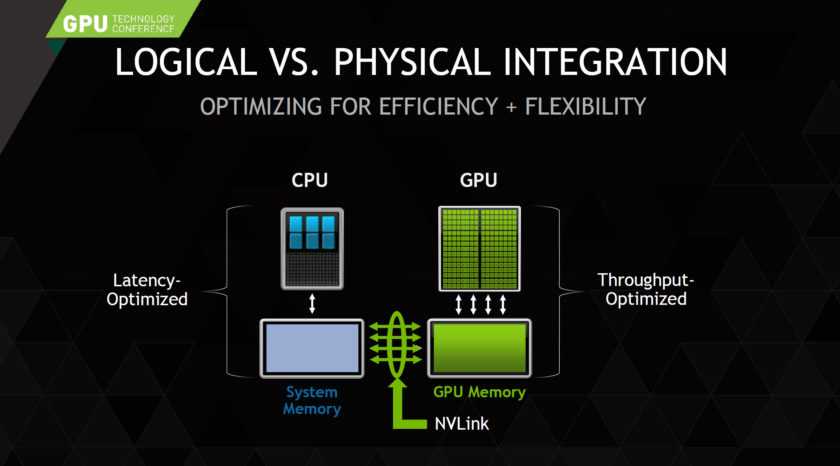
Все современные GPU оснащены разделяемой памятью, которая одновременно доступна всем «вычислителям» одного мультипроцессора, что, по сути, является программно-управляемым кэшем. Он идеально подходит для алгоритмов с высокой степенью локальности



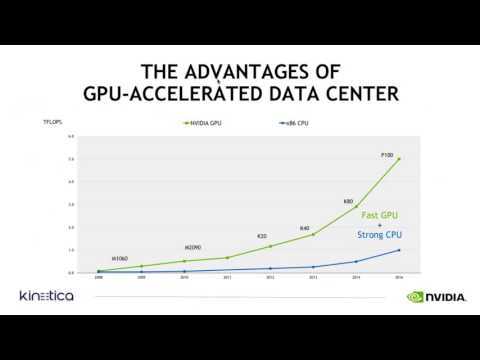

Скорость доступа к этой памяти в несколько раз превосходит возможности L1 кэша CPU.
Ещё одной важной особенностью GPU по сравнению с CPU является то, что количество доступных регистров можно менять динамически (от 64 до 256 на один поток), тем самым позволяя снижать нагрузку на подсистему памяти. Для сравнения, в архитектурах x86 и х64 используется 16 универсальных регистров и 16 AVX регистров на один поток.
Наличие нескольких специализированных аппаратных модулей на GPU для одновременной работы над совершенно разными задачами: аппаратная обработка изображений (ISP) на Jetson, асинхронное копирование в GPU и обратно, вычисления на GPU, аппаратное кодирование и декодирование видео (NVENC, NVDEC), тензорные ядра для нейросетей, OpenGL, DirectX, Vulkan для визуализации.
Но, как результат всех перечисленных выше преимуществ GPU перед CPU, за всё это приходится платить высокими требованиями к параллельности алгоритмов. Если для максимальной загрузки CPU достаточно десятков потоков, то для полной загрузки GPU нужны десятки тысяч потоков.
Встраиваемые (embedded) приложения
Следует помнить и о таком типе задач, как встраиваемые решения. Здесь GPU уже конкурируют со специализированными устройствами, такими как FPGA (программируемая пользователем вентильная матрица) и ASIC (интегральная схема специального назначения). Основным преимуществом GPU перед прочими решениями является их существенно большая гибкость. Для отдельных встраиваемых решений GPU может быть серьёзной альтернативой, так как мощные многоядерные процессоры не проходят по допустимым требованиям к размеру и энергопотреблению.
Скрипт как средство имитации загрузки CPU: изучаем особенности
Для имитации загрузки CPU в тестовой среде воспользуемся скриптом и понаблюдаем за поведением виртуальной машины. Для начала необходимо запустить VMware vSphere Power CLI, после чего станет доступным окно командной строки, в котором и запускается скрипт Start CPU Test.
Рисунок 1. Окно командной строки
После полной отработки скрипта запускаются удаленные рабочие столы двух виртуальных машин.
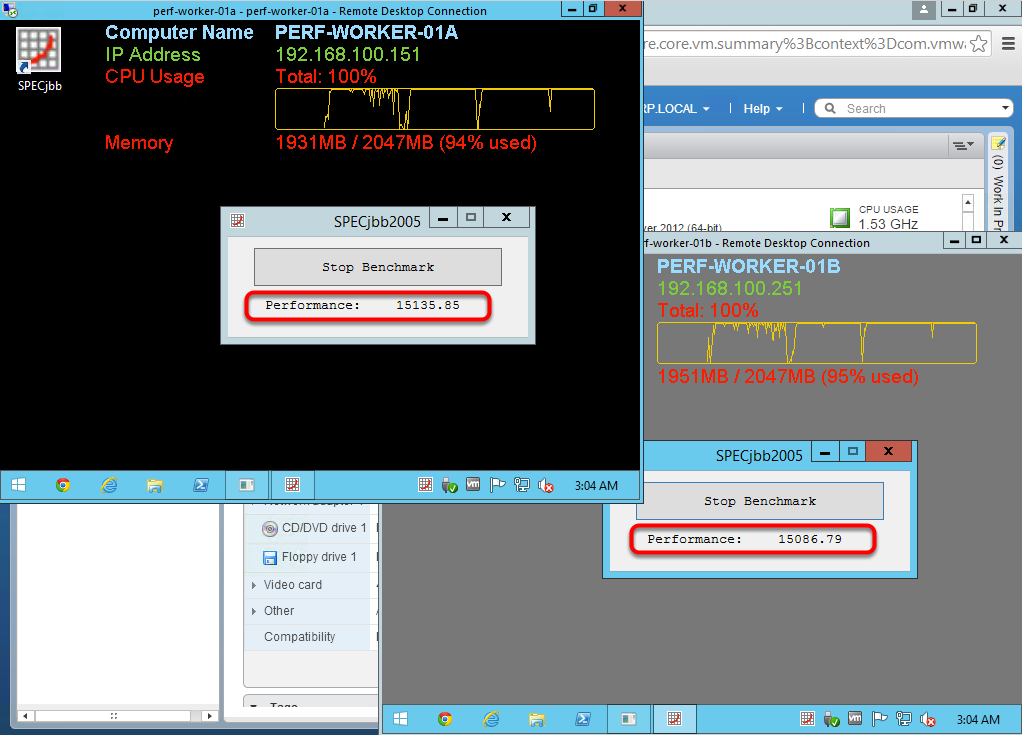
Рисунок 2. Запуск удаленных рабочих столов виртуальных машин
Скрипт имитирует ресурсоемкий процесс загрузки CPU виртуальных машин: PERF-WORKER-01Aи PERF-WORKER-01B, а графический интерфейс отображает значения производительности в режиме реального времени. Как видите, отметка производительности близка к значению 15 000.
Переключаемся в окно vSphere, переходим в закладку мониторинга производительности машины PERF-WORKER-01A. Поскольку интересны расширенные параметры, необходимо выбрать опцию Advanced –> Chart Options.
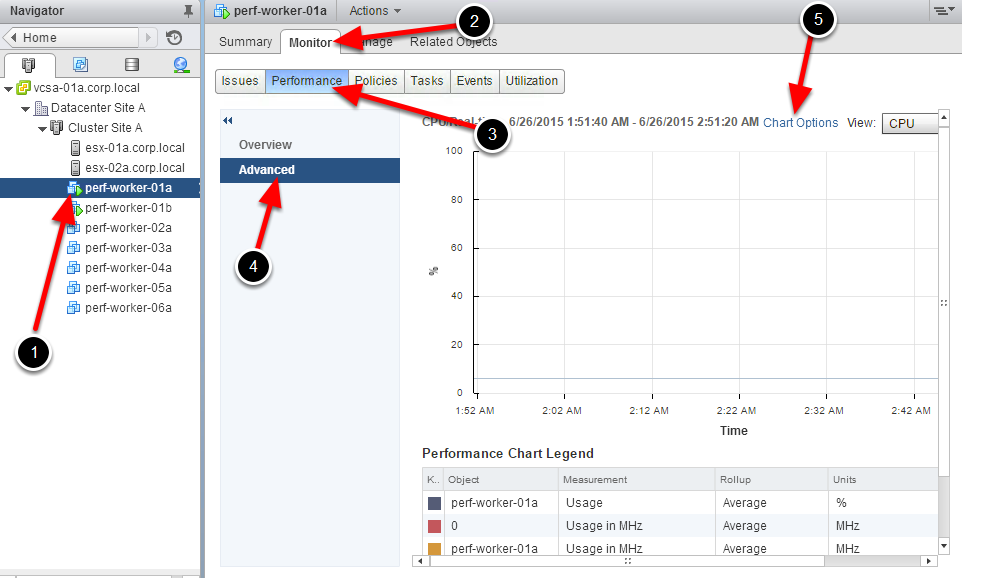
Рисунок 3. Обзор расширенных параметров в vSphere
Здесь выбираются необходимые счетчики, полезные для отслеживания производительности процессора.
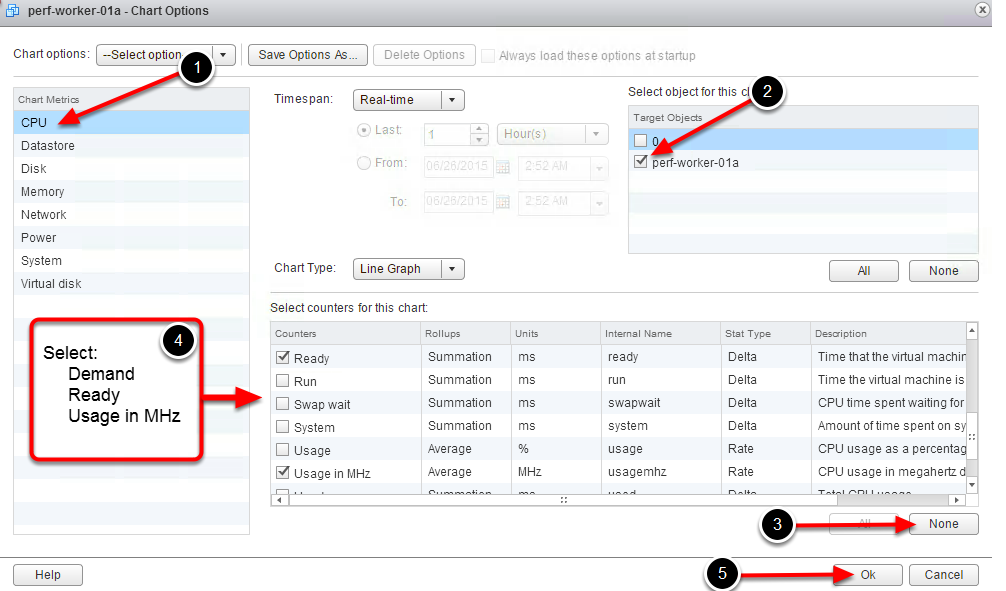
Рисунок 4. Выбор соответствующих счетчиков производительности
При расследовании проблем производительности CPU стоит обратить внимание на следующие счетчики:
- Demand – количество CPU виртуальной машины, необходимых (требуемых) для использования.
- Ready – показатель времени, в течение которого виртуальная машина готова запуститься, но не может в силу недостаточности физически ресурсов.
- Usage – количество CPU виртуальной машины, фактически разрешенных для использования в текущий момент.
Для выбора Demand, Ready, Usage и других счетчиков необходимо перейти в раздел метрик CPU и указать необходимые элементы, после чего нажать кнопку ОК.
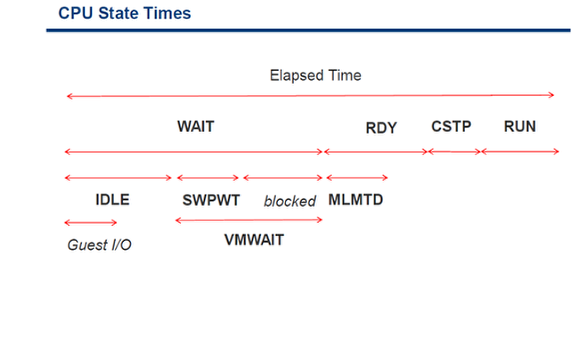
Рисунок 5. Показатели CPU State
Виртуальные машины могут находиться в одном из представленных ниже состояний, которые отслеживаем с помощью соответствующих счетчиков:
- Wait (VMWAIT) – такое состояние фиксируется, когда гостевая ОС виртуальной машины находится в состоянии простоя или ожидается выполнение задач на уровне vSphere. К примеру, vCPU может перейти в режим Wait в случае, если ожидается завершение операций ввода-вывода или выполнение «свопирования» на уровне ESX. Иными словами, такой счетчик отображает процент времени, который виртуальная машина потратила на ожидание, пока ядро ESX выполняло какие-либо операции.
- Ready (RDY) – главная составляющая производительности процессора. Процессор может находиться в состоянии RDY, когда виртуальная машина готова к запуску, но в силу недостаточности физических ресурсов хоста запуститься не может. Одной из причин может быть установленный на CPU лимит (выше мы говорили об этом), или лимит ресурсного пула.
- Co-Stop (CSTP): этот статус соотносится со временем, когда виртуальная машина готова исполнять команды, но вынуждена ждать высвобождения других vCPU для возможности их одновременного использования.
- Run (исполнение): показывает, что виртуальная машина «исполняется» в системе.
Исходя из рассмотренных статусов и счетчиков, нелишним будет ознакомиться с одной важной формулой. Она верна для отдельно взятой VM, которая либо простаивает и находится в ожидании (%WAIT), либо готова исполнять команды, но CPU занят (%RDY), либо ожидает высвобождения нескольких процессоров (%CSTP), либо исполняется в системе (%RUN)
%WAIT + %RDY + %CSTP + %RUN = 100%
Список процессоров с интегрированной графикой AMD Radeon R7 Graphics
| Процессор | Тип | Кодовое название | Дата запуска | Кол-во ядер | Макс. частота |
|---|---|---|---|---|---|
| AMD A8-7650K | Desktop | Kaveri | 14 January 2014 | 4 | 3.8 GHz |
| AMD A10-7850K | Desktop | Kaveri | 14 January 2014 | 4 | 4 GHz |
| AMD A10-7700K | Desktop | Kaveri | 14 January 2014 | 4 | 3.8 GHz |
| AMD FX-7600P | Laptop | Kaveri | 4 June 2014 | 4 | 3.6 GHz |
| AMD FX-7500 | Laptop | Kaveri | 4 June 2014 | 4 | 3.3 GHz |
| AMD A10-7870K | Desktop | Kaveri | May 2015 | 4 | 4.1 GHz |
| AMD Pro A12-8800B | Laptop | Carrizo | 3 June 2015 | 4 | 3.4 GHz |
| AMD FX-8800P | Laptop | Carrizo | 3 June 2015 | 4 | 3.4 GHz |
| AMD A10-7890K | Desktop | Kaveri | January 2016 | 4 | 4.3 GHz |
| AMD PRO A12-9830B | Laptop | Bristol Ridge | 24 October 2016 | 4 | 3.7 GHz |
| AMD PRO A12-9800B | Laptop | Bristol Ridge | 24 October 2016 | 4 | 3.6 GHz |
| AMD FX-9830P | Laptop | Bristol Ridge | 1 June 2016 | 4 | 3.7 GHz |
| AMD FX-9800P | Laptop | Bristol Ridge | 1 June 2016 | 4 | 3.6 GHz |
| AMD A12-9700P | Laptop | Bristol Ridge | 1 June 2016 | 4 | 3.4 GHz |
| AMD A8-9600 | Desktop | Bristol Ridge | 27 July 2017 | 4 | 3.4 GHz |
| AMD A12-9800E | Desktop | Bristol Ridge | 5 September 2016 | 4 | 3.8 GHz |
| AMD A12-9800 | Desktop | Bristol Ridge | 27 July 2017 | 4 | 4.2 GHz |
| AMD A10-9700E | Desktop | Bristol Ridge | 5 September 2016 | 4 | 3.5 GHz |
| AMD A10-9700 | Desktop | Bristol Ridge | 27 July 2017 | 4 | 3.8 GHz |
| AMD A12-9730P | Laptop | Q2 2016 | 4 | 3.5 GHz | |
| AMD PRO A12-9800 | Desktop | 3 October 2016 | 4 | 4.2 GHz | |
| AMD PRO A12-9800E | Desktop | 3 October 2016 | 4 | 3.8 GHz | |
| AMD PRO A10-9700 | Desktop | 3 October 2016 | 4 | 3.8 GHz | |
| AMD PRO A10-9700E | Desktop | 3 October 2016 | 4 | 3.5 GHz | |
| AMD PRO A8-9600 | Desktop | 3 October 2016 | 4 | 3.4 GHz | |
| AMD PRO A10-9730B | Laptop | 24 October 2016 | 4 | 3.5 GHz | |
| AMD PRO A10-9700B | Laptop | 24 October 2016 | 4 | 3.4 GHz | |
| AMD PRO A12-8870 | Desktop | Q3 2016 | 4 | 4.2 GHz | |
| AMD PRO A12-8870E | Desktop | 4 | 3.8 GHz | ||
| AMD PRO A10-8850B | Desktop | 4 | 4.1 GHz | ||
| AMD PRO A10-8770 | Desktop | Q3 2016 | 4 | 3.8 GHz | |
| AMD PRO A10-8770E | Desktop | Q3 2016 | 4 | 3.5 GHz | |
| AMD PRO A10-8750B | Desktop | 4 | 4 GHz | ||
| AMD PRO A8-8650B | Desktop | 4 | 3.9 GHz | ||
| AMD PRO A12-8830B | Laptop | Q3 2016 | 4 | 3.4 GHz | |
| AMD A10-7860K | Desktop | 4 | 4 GHz | ||
| AMD A10-7800 | Desktop | 4 | 3.9 GHz | ||
| AMD A8-7670K | Desktop | 4 | 3.9 GHz | ||
| AMD A8-7600 | Desktop | 4 | 3.8 GHz | ||
| AMD A10 PRO-7850B | Desktop | 4 | 4 GHz | ||
| AMD A10 PRO-7800B | Desktop | 4 | 3.9 GHz | ||
| AMD A8 PRO-7600B | Desktop | 4 | 3.8 GHz | ||
| AMD Opteron X3216 | Server | Toronto | Q2’17 | 2 | 3000 MHz |
| AMD A8-7500 | Desktop | Kaveri | 4 | ||
| AMD RX-421BD | Embedded | Merlin Falcon | 21 October 2015 | 4 | 3400 MHz |
| AMD RX-427BB | Embedded | Bald Eagle | 20 May 2014 | 4 | 3600 MHz |
Все в небо! Ближе к облакам!
- При этом обучение нейросети относительно слабо масштабируется горизонтально. Т.е. мы не можем взять 1000 мощных компьютеров и получить ускорение обучения в 1000 раз. И даже в 100 не можем (по крайней мере пока не решена теоретическая проблема ухудшения качества обучения на большом размере батча). Нам вообще довольно сложно что-то раздавать по нескольким компьютерам, поскольку как только падает скорость доступа к единой памяти, в которой лежит сеть — катастрофически падает скорость ее обучения. Поэтому если у исследователя будет доступ к 1000 мощных компьютеров
на халяву, он, безусловно, скоро их все займет, но скорее всего (если там не infiniband + RDMA) обучаться там будет много нейросетей с разными гиперпараметрами. Т.е. общее время обучения будет лишь в несколько раз меньше, чем при 1 компьютере. Там возможны и игра с размерами батча, и дообучение, и прочие новые модные технологии, но основной вывод — да, при увеличении количества компьютеров эффективность работы и вероятность достичь результата будут расти, но не линейно. Причем сегодня время исследователя Data Science стоит дорого и часто если можно потратить много машин (пусть неразумно), но получить ускорение — это делается (см. пример с 1, 2 и 4 дорогими V100 в облаках чуть ниже).
Какова роль видеопамяти в системе
Наверное, нет нужды говорить о том, что память графического адаптера в чем-то очень сильно напоминает основную оперативную память компьютерной системы.
На нее возложены практически те же функции загрузки основных программных компонентов программ и приложений с передачей вычислений графическому процессору. Понятно, что при малом объеме, как ни пытайся, загрузить туда больше того, на что она рассчитана, не получится. Поэтому многие игры не то, что функционируют со сбоями, так иногда еще и не работают вообще. Но проблема того, как увеличить видеопамять видеокарты, как оказывается, решается достаточно просто. Правда, назвать это именно увеличением нельзя, поскольку физически размер видеопамяти не изменяется.
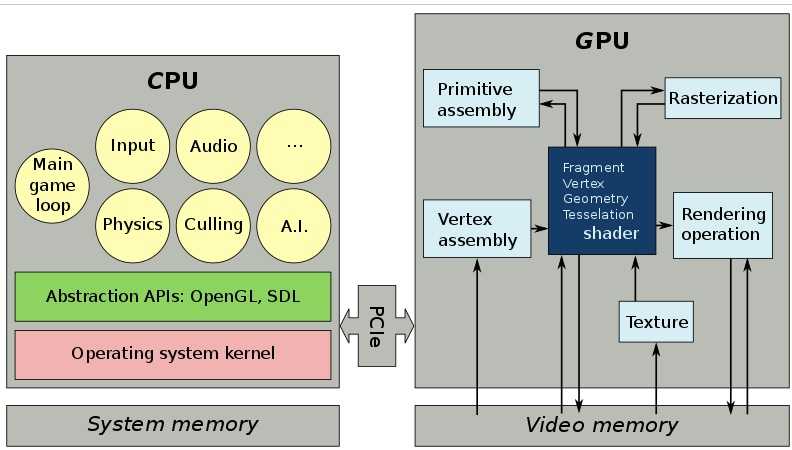
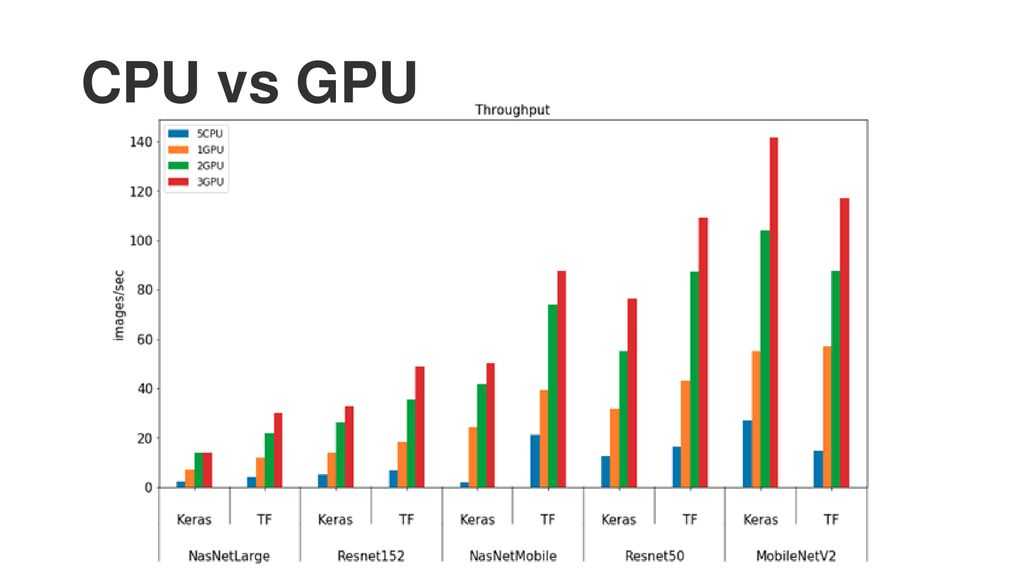
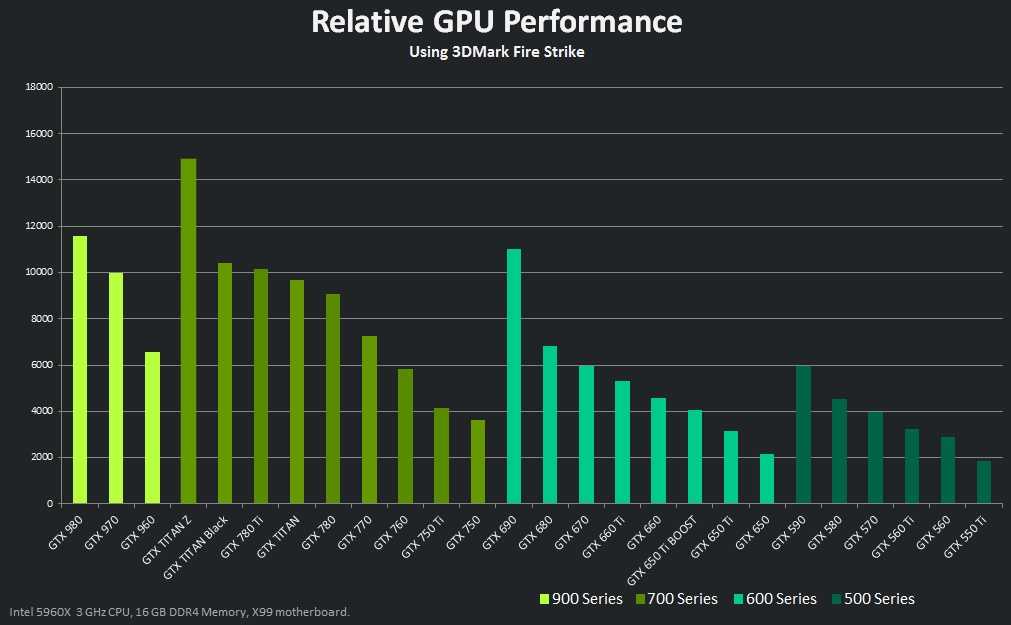
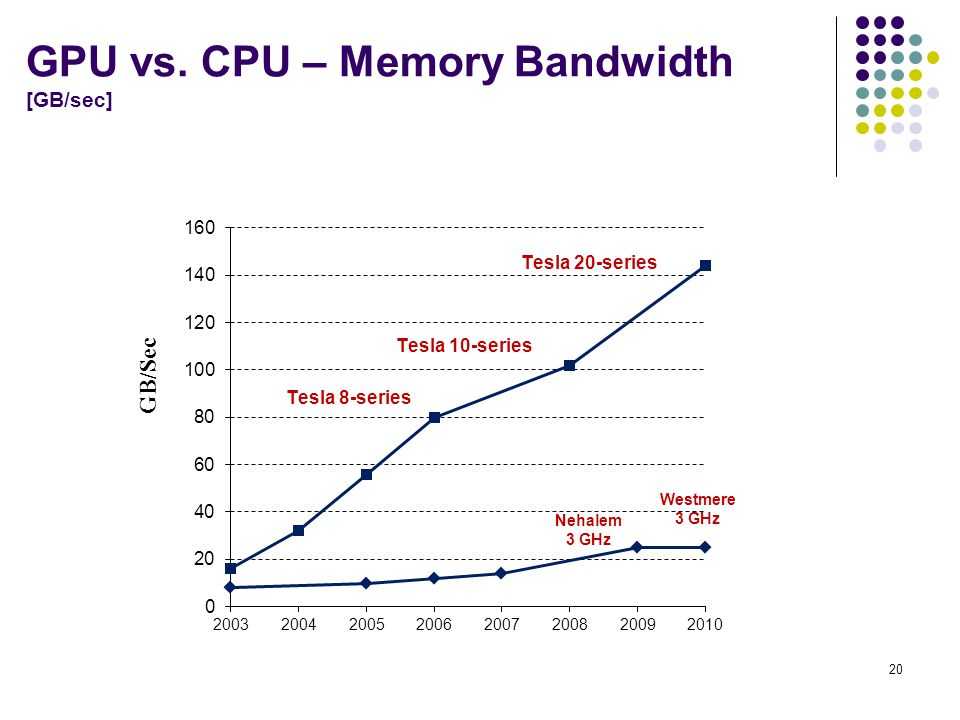
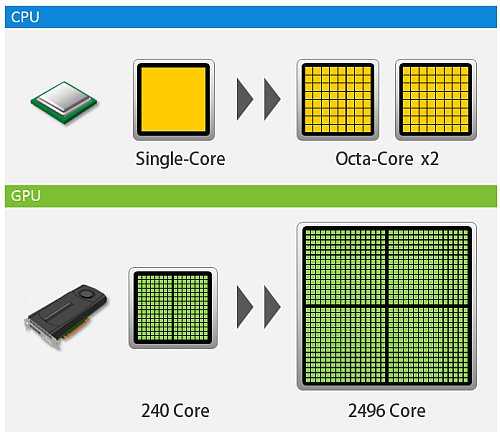
Приложение №3 Программные модели SIMD и SIMT, или почему у GPU так много потоков
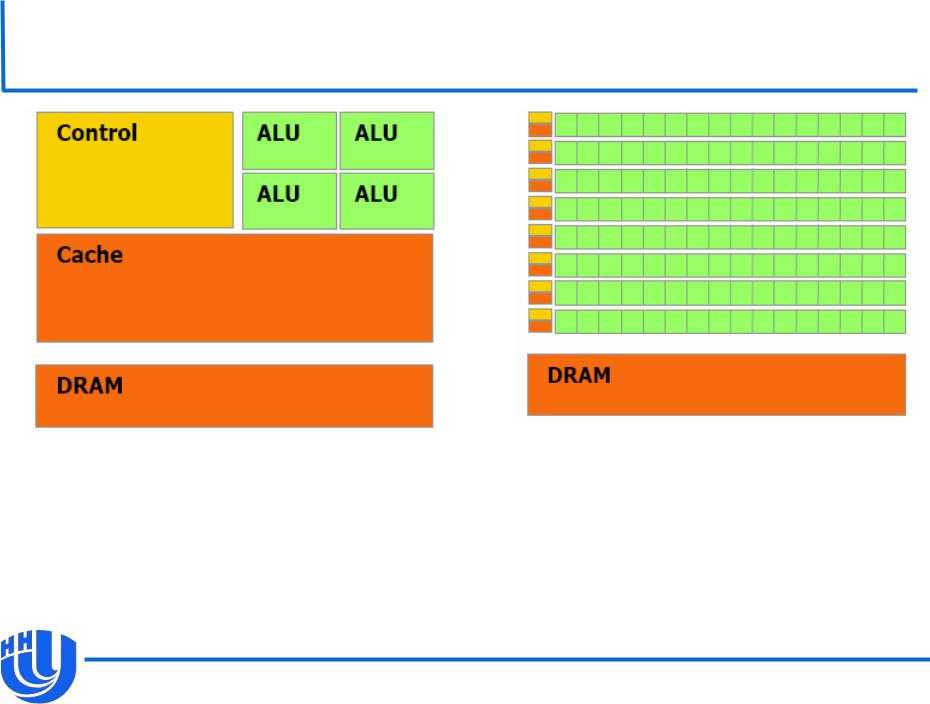
Для повышения производительности CPU используются SIMD (single instruction, multiple data) инструкции. Одна такая инструкция позволяет выполнить несколько однотипных операций над вектором данных. Плюсом этого подхода является рост производительности без существенной модификации instruction pipeline. Все современные CPU, как x86, так и ARM, имеют SIMD инструкции. Минусом данного подхода является сложность программирования. Основной подход к SIMD программированию — это использование intrinsic. Intrinsic – это встроенные функции компилятора, которые содержат одну или несколько SIMD-инструкций, плюс инструкции для подготовки параметров. Intrinsic формируют низкоуровневый язык, очень близкий к ассемблеру, который крайне трудоёмок в использовании. Кроме того, для каждого набора инструкций у каждого компилятора есть свой набор Intrinsic. Выходит новый набор инструкций – нужно всё переписывать, переходим на новую платформу (с x86 на ARM) нужно переписывать, переходим на другой компилятор — опять нужно всё переписывать.
Программная модель для GPU называется SIMT (Single instruction, multiple threads). Одна инструкция синхронно исполняется в нескольких потоках. Этот подход можно считать развитием SIMD. Скалярная программная модель скрывает векторную суть машины, автоматизируя и упрощая многие операции. Именно поэтому для большинства программистов писать привычный скалярный код на SIMT проще, чем векторный на чистом SIMD.
CPU и GPU по-разному решают вопрос латентности инструкций при исполнении их на конвейере. Латентность инструкции – это через сколько тактов следующая инструкция может воспользоваться её результатами. Например, если латентность инструкции равна 3 и CPU может запускать 4 таких инструкции за такт, то за 3 такта процессор запустит 2 зависимых инструкции или 12 независимых. Чтобы избежать такого существенного простоя, все современные процессоры используют внеочередное исполнение инструкций. В этом случае процессор в заданном окне CPU анализирует зависимости инструкций и запускает независимые инструкции вне очереди.
GPU использует другой подход, основанный на многопоточности. У GPU есть pool потоков. Каждый такт выбирается один поток и из него выбирается одна инструкция, которая отправляется на исполнение. На следующем такте выбирается следующий поток и так далее. После того, как из всех потоков в pool была запущена одна инструкция, возвращаемся к первому потоку и т.д. Такой подход позволяет скрыть латентность зависимых инструкций за счёт исполнения инструкций из других потоков.
При программировании GPU можно условно выделить два уровня потоков. Первый уровень потоков отвечает за формирование SIMT. Для GPU NVIDIA – это 32 соседних потока, которые называются warp. Известно, что SM для Turing поддерживает 1024 потока. Это количество распадается на 32 настоящих потока, в рамках которых организуется SIMT исполнение. Настоящие потоки могут в один момент времени исполнять разные инструкции, в отличие от SIMT.
Таким образом, стриминговый мультипроцессор Turing – это векторная машина с размером вектора 32 и 32-мя независимыми потоками. Ядро CPU с AVX – это векторная машина с размером вектора 8 и двумя независимыми потоками.
Определяем тип графического адаптера
Прежде чем заниматься поиском решения проблемы и ответа на вопрос о том, как увеличить видеопамять, нужно определиться с типом установленного в системе графического адаптера.

Они бывают двух типов: интегрированные (встроенные в материнскую плату) и дискретные (вставляемые в специальные слоты).
Визуально интегрированный адаптер можно определить по наличию рядом находящихся разъемов HDMI, USB, LAN и т.д.
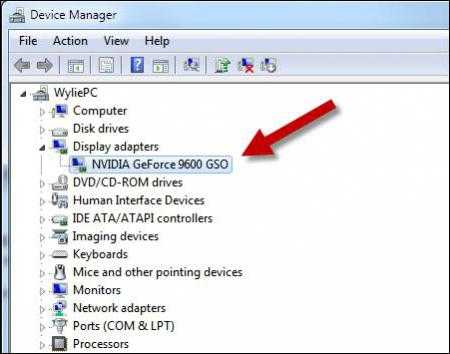
Получить более подробную информацию можно в «Диспетчере устройств», вызвав его либо из «Панели управления», либо из консоли «Выполнить» (Win +R) командой devmgmt.msc.
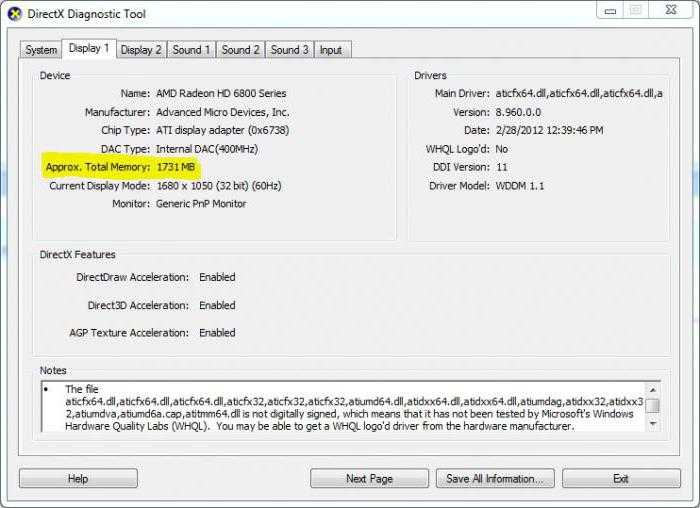
Однако наиболее полные данные содержатся в диалоговом окне DirectX, вызываемом из меню «Выполнить» строкой dxdiag. На вкладке «Экран» и будет представлена вся информация. Кстати сказать, узнать основные характеристики интегрированных видеоадаптеров можно только таким способом.
Заключение
С выпуском процессоров семейства Rocket Lake компания Intel, как и обещала, подтянула уровень IPC в сравнении с предыдущими поколениями CPU. Новые процессоры, в том числе и протестированные сегодня Core i5-11500 и Core i5-11400, в действительности демонстрируют новый уровень производительности на ядро. Но это не единственный положительный момент решений с микроархитектурой Cypress Cove. Своевременно введенная поддержка PCI Express 4.0 с увеличением количества линий до 20-ти, новый двухрежимный контроллер памяти и обновленная графика UHD Graphics 750(730), а также выпуск набора логики Intel Z590 — главные особенности текущего обновления.
Что касается непосредственно процессоров Core i5-11500 и Core i5-11400, то на основе проведенного тестирования можно сказать, что данные CPU отличаются друг от друга незначительно. В частности, различия между ними минимальны с точки зрения производительности. При этом стоит признать, что старший Core i5-11500 имеет более комфортный и покладистый характер работы. В отличии от Core i5-11400, ему свойственны более низкие энергопотребление и нагрев, а также более легкий разгон оперативной памяти. Впрочем, на стороне Core i5-11400 будет играть более доступная стоимость этого шестиядерного CPU. При цене в $192 за Core i5-11500 и $182 за Core i5-11400 на сегодняшний день оба этих процессора одинаково хороши.
Плюсы:
- высокая производительность на ядро;
- поддержка PCI Express 4.0 в количестве 20-ти линий;
- двухрежимный контроллер памяти с широким диапазоном разгона ОЗУ;
- совместимость с платформой LGA1200 и чипсетом Intel Z490;
- наличие инструкций AVX-512 для рабочих и игровых приложений;
- доступная стоимость в сравнении с конкурентными решениями.
Минусы:
высокое энергопотребление и нагрев.
Образцы на тестирование предоставлены iRU и Ситилинк.